Bab 11 Analisis Data Penelitian dengan R

11.1 Tujuan Pembelajaran
CPMK 11
Mahasiswa mampu menerapkan keterampilan pemrograman R untuk analisis data penelitian pendidikan fisika.
Sub-CPMK
- Mahasiswa mampu menerapkan statistika parametrik dengan program R.
- Mahasiswa mampu menerapkan statistika nonparametrik dengan program R.
- Mahasiswa mampu menerapkan statistika multivariat sederhana dengan program R.
- Mahasiswa mampu menerapkan analisis butir dengan teori tes klasik dengan program R.
Deskripsi Isi Bahan Ajar
Bab 11 ini membahas tentang:
- Statistika parametrik dengan R.
- Statistika non-parametrik dengan R.
- Statistika multivariat dengan R.
- Analisis butir teori tes klasik dengan R.
Waktu Pembelajaran
Alokasi Waktu = 3 x 50 menit (3 SKS)
| Kegiatan | Alokasi Waktu |
|---|---|
| Ceramah dan Diskusi Interaktif | 50 menit |
| Praktik Analisis Data pada R | 50 menit |
| Konsultasi Praktik R | 50 menit |
| Presentasi individu | 50 menit |
Petunjuk Penggunaan Bahan Ajar
Langkah-langkah pembelajaran.
Pelajari statistika parametrik, statistika nonparametrik, statistika multivariat, dan analisis tes teori klasik dengan R. Terapkan pengetahuan Anda pada proyek individu yang disajikan di akhir bab 11 ini. Konsultasikanlah kesulitan Anda selama praktik pada pengajar mata kuliah ini. Anda bisa bekerja dengan IDE RStudio secara offline maupun online.Sumber Belajar yang Dibutuhkan.
Laptop (Notebook), jaringan internet
Tujuan Akhir (Performance Objective)
Setelah menyelesaikan modul ini, mahasiswa mampu memahami dan menerapkan teknik analisis statistika parametrik, statistika nonparametrik, statistika multivariat, dan analisis teori tes klasik dengan R.
11.2 Statistika Parametrik dengan R
Definisi dari statistika parametrik dan apa perbedaannya dengan nonparametrik. Perbedaan utama antara keduanya adalah pemenuhan asumsi normalitas dari data yang sedang kita analisis. Jika data kita memenuhi asumsi normalitas atau berdistribusi normal, maka teknik statistika yang disarankan adalah statistika parametrik. Daftar lebih lengkapnya dapat dilihat pada tabel di bawah ini.
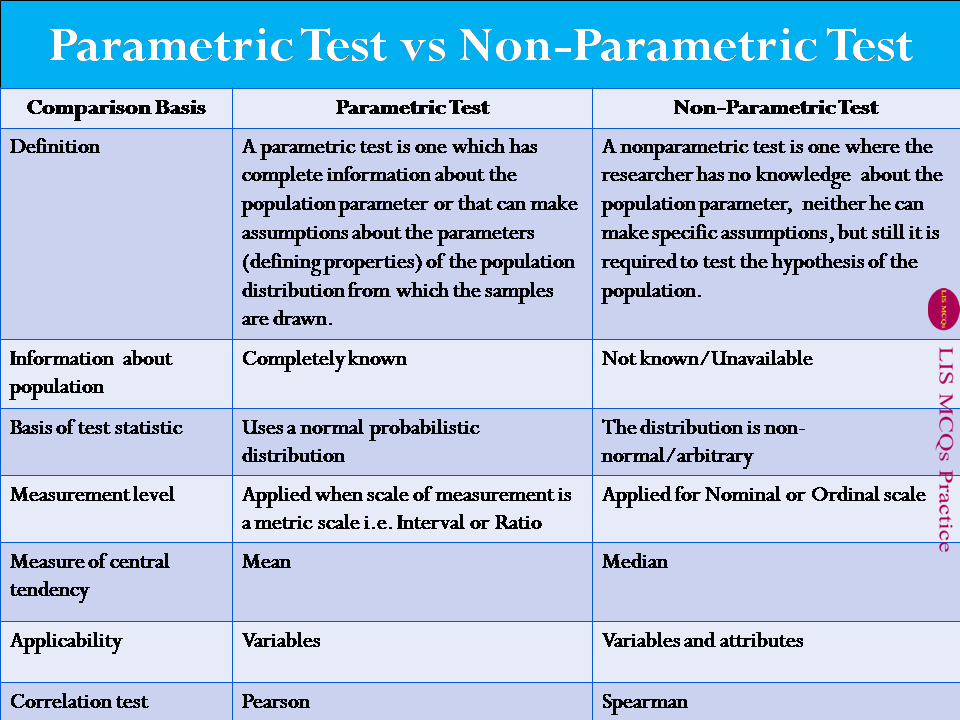
Jenis-jenis teknik analisis statistika parametrik dan nonparametrik. Kita bisa menggunakan kedua pendekatan ini tergantung dari tujuan analisis data yang ingin kita lakukan. Baik statistika parametrik maupun nonparametrik bisa kita lakukan di R sehingga jika kita menemukan pelanggaran asumsi normalitas di dalam data kita maka kita bisa memilih alternatif dari analisis parametrik dengan metode yang dikembangkan oleh nonparametrik. Berikut ini adalah ekuivalensi metode analisis antara statistika parametrik dan nonparametrik yang bisa kita gunakan untuk analisis statistika inferensial.

Uji T Satu Sampel
Uji T adalah metode statistika yang digunakan untuk menentukan apakah terdapat perbedaan rata-rata suatu sampel dengan nilai yang diketahui atau rata-rata antara dua sampel.
Contoh:
Membuat dataframe pensekoran spheredata. Disini kita ingin menguji apakah nilai rata-rata skor FCI berbeda dengan nilai sama dengan 10. Langkah pertama adalah kita mempersiapkan datanya terlebih dahulu.
library(spheredata)
skorFCI <- rowSums(binary(FCI, FCIkey))
skorFMCE <- rowSums(binary(FMCE, FMCEkey))
skorRRMCS <- rowSums(binary(RRMCS, RRMCSkey))
skorFMCI <- rowSums(binary(FMCI, FMCIkey))
skorMWCS <- rowSums(binary(MWCS, MWCSkey))
skorTCE <- rowSums(binary(TCE, TCEkey))
skorSTPFASL <- rowSums(binary(STPFASL, STPFASLkey))
skorCLASS <- rowSums(CLASS)
skorSAAR <- rowSums(SAAR)
df <- data.frame(demographic,
physicsidentity,
literacy,
FCI = skorFCI,
FMCE = skorFMCE,
RRMCS = skorRRMCS,
FMCI = skorFMCI,
MWCS = skorTCE,
TCE = skorTCE,
STPFASL = skorSTPFASL,
CLASS = skorCLASS,
SAAR = skorSAAR,
teachersjudgment)## 'data.frame': 497 obs. of 29 variables:
## $ STUDID : chr "A1001" "A1002" "A1003" "A1004" ...
## $ SCH : num 1 1 1 1 1 1 1 1 1 1 ...
## $ COH : num 1 1 1 1 1 1 1 1 1 1 ...
## $ GDR : num 1 2 1 2 1 2 2 2 2 2 ...
## $ AGE : num 3 1 2 3 2 2 2 2 2 2 ...
## $ FATHOCC : num 1 4 4 1 1 1 1 4 1 2 ...
## $ MOTHOCC : num 9 8 8 1 1 7 1 5 1 2 ...
## $ FATHEDU : num 4 4 3 2 3 4 4 2 4 4 ...
## $ MOTHEDU : num 5 4 4 2 3 2 3 1 3 4 ...
## $ FATHINC : num 7 10 2 6 10 9 8 10 10 11 ...
## $ MOTHINC : num 12 12 12 6 10 4 8 5 9 11 ...
## $ SIBL : num 2 2 0 3 2 2 2 2 1 2 ...
## $ DOM : num 1 1 1 1 1 2 2 1 1 1 ...
## $ PHYIDE1 : num 3 2 2 3 3 2 1 2 2 2 ...
## $ PHYIDE2 : num 1 2 1 1 1 1 1 1 1 1 ...
## $ LIT1 : num 1 1 1 2 2 1 1 1 1 1 ...
## $ LIT2 : num 1 1 1 1 1 2 1 1 1 1 ...
## $ FCI : num 6 10 10 4 2 7 9 4 6 7 ...
## $ FMCE : num 30 15 45 45 23 0 47 47 47 39 ...
## $ RRMCS : num 15 23 10 9 18 4 13 14 11 15 ...
## $ FMCI : num 0 13 11 11 0 0 12 12 6 0 ...
## $ MWCS : num 14 8 18 16 8 10 17 18 12 18 ...
## $ TCE : num 14 8 18 16 8 10 17 18 12 18 ...
## $ STPFASL : num 22 12 15 15 1 9 13 15 13 15 ...
## $ CLASS : num 135 120 121 105 106 84 127 128 124 123 ...
## $ SAAR : num 46 51 47 45 34 39 50 48 49 47 ...
## $ FINTEST1 : num 48 38 79 62 44 26 92 60 44 42 ...
## $ FINTEST2 : num 56 61 73 59 40 32 86 68 46 43 ...
## $ TEACHPRED: num 0 0 1 1 0 0 1 1 0 0 ...Uji t satu sampel bisa kita hitung dengan menggunakan fungsi t.test(). Kita ingin menguji apakah rata-rata sampel kita berbeda dengan nilai “mu=10” dengan uji t satu sampel.
Contoh:
##
## One Sample t-test
##
## data: df$FCI
## t = -9.1015, df = 496, p-value < 2.2e-16
## alternative hypothesis: true mean is not equal to 10
## 95 percent confidence interval:
## 7.123009 8.144596
## sample estimates:
## mean of x
## 7.633803Hasilnya menunjukkan bahwa nilai p-value yang kurang dari taraf signifikansi (\(\alpha\)) sebesar 5% artinya adalah terdapat perbedaan rata-rata sampel dengan nilai 10.
Uji T Dua Sampel Berpasangan
Misalkan kita melakukan eksperimen pembelajaran dengan desain eksperimen pretest-posttest. Kita memiliki data FCI di dalam dataset spheredata. Akan tetapi, skor FCI disini bukanlah merupakan nilai pretest atau postest. Seolah-olah data FCI di dalam dataset spheredata adalah data pretest. Dan kita membangkitkan data dengan mengalikan skor FCI dengan koefisien 1.5 untuk data posttestnya.
Contoh:
## pretest_FCI postest_FCI
## 1 6 9.0
## 2 10 15.0
## 3 10 15.0
## 4 4 6.0
## 5 2 3.0
## 6 7 10.5##
## Paired t-test
##
## data: pretest_FCI and postest_FCI
## t = -29.363, df = 496, p-value < 2.2e-16
## alternative hypothesis: true mean difference is not equal to 0
## 95 percent confidence interval:
## -4.072298 -3.561505
## sample estimates:
## mean difference
## -3.816901Nilai p-value kurang dari taraf signifikansi (\(\alpha\)) sebesar 5% artinya adalah terdapat perbedaan signifikan dari skor FCI antara pretest dan posttest.
Uji T Dua Sampel Independen
Sekarang kita ingin menguji apakah dua sampel independen memiliki perbedaan rata-rata secara signifikan. Independen artinya kedua sampel tidak memiliki keterkaitan dan jumlah datanya tidak harus sama atau berpasangan. Misalnya kita ingin menguji apakah skor FCI antara sekolah 1 dan sekolah 4 memiliki perbedaan rata-rata secara signifikan.
Contoh:
df_sekolah1 <- subset(df, SCH == 1)
df_sekolah4 <- subset(df, SCH == 4)
t.test(df_sekolah1$FCI, df_sekolah4$FCI, var.equal = TRUE)##
## Two Sample t-test
##
## data: df_sekolah1$FCI and df_sekolah4$FCI
## t = 0.97891, df = 283, p-value = 0.3285
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -0.5557721 1.6554471
## sample estimates:
## mean of x mean of y
## 7.923077 7.373239Hasil menunjukkan bahwa nilai p-value lebih besar daripada taraf signifikansi (\(\alpha\)) 0.05.
One Way Analysis of Variance (ANOVA)
Uji t hanya bisa digunakan untuk membandingkan 2 kelompok. Bagaimana jika perbandingan dilakukan antara lebih dari 2 kelompok? Jawabannya adalah analysis of variance (ANOVA). Uji t sebenarnya adalah kasus khusus dari ANOVA untuk perbandingan 2 kelompok saja. Analisis anova bisa kita lakukan di R dengan fungsi aov().
Misalkan kita ingin menguji apakah terdapat perbedaan skor FCI antara sekolah 1, 2, 3, dan 4.
Contoh:
## Df Sum Sq Mean Sq F value Pr(>F)
## SCH 1 115 115.29 3.449 0.0639 .
## Residuals 495 16546 33.43
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Nilai p-value lebih besar daripada taraf signifikansi (\(\alpha\)) 0.05 sehingga diinterpretasikan bahwa kita tidak menemukan perbedaan skor FCI secara signifikan antara sekolah.
Asumsi homogenitas (bahwa varians antar kelompok adalah sama secara statistik) dapat kita lihat secara visualisasi berikut ini.
Contoh:
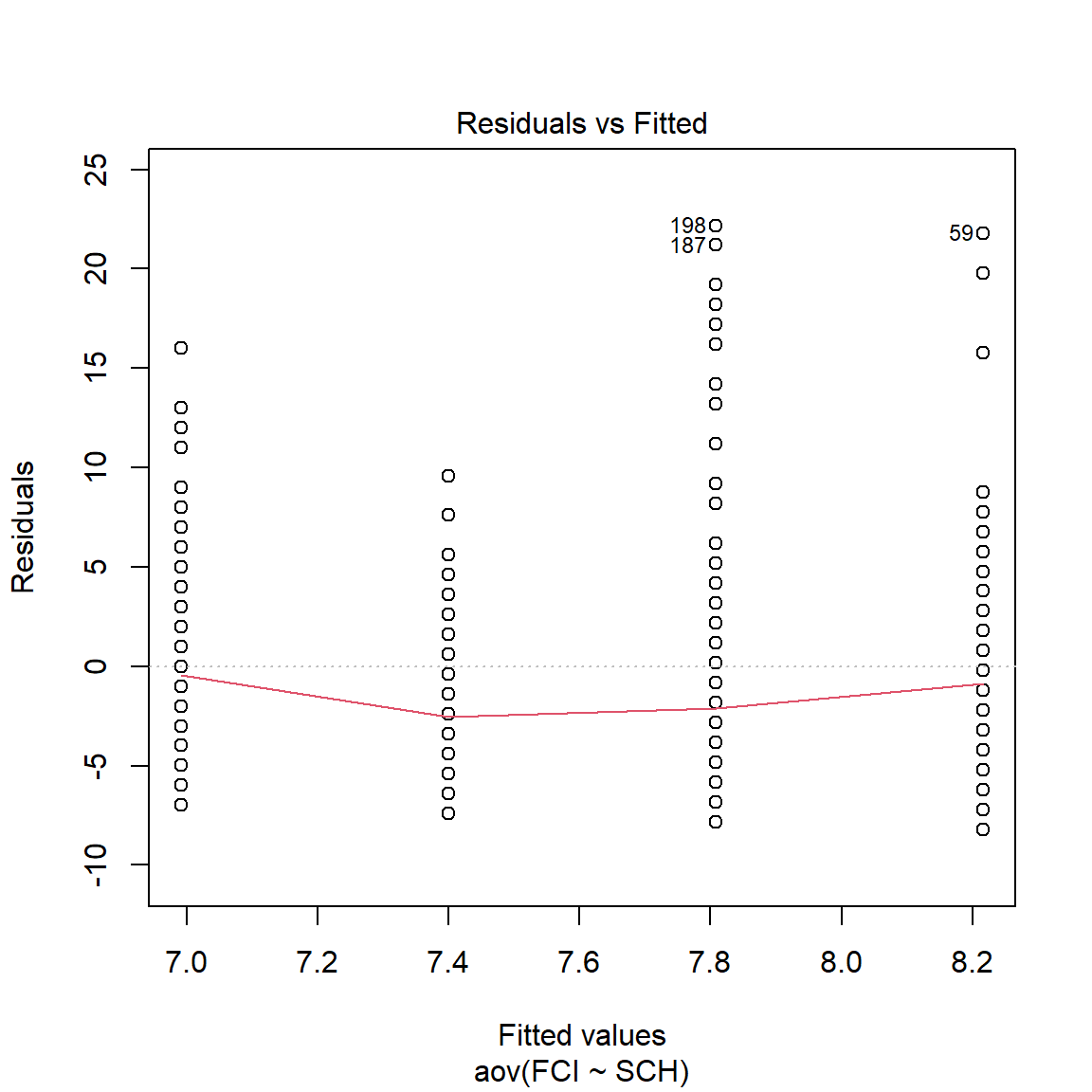
Nilai skor FCI pada siswa 198, 187, dan 59 merupakan outlier (nilai pencilan) yang bisa mengganggu normalitas data.
Kita bisa melakukan uji homogenitas dengan Levene’s test dengan fungsi leveneTest() dari package “car”.
Contoh:
## Warning: package 'car' was built under R version 4.5.3## Loading required package: carData## Warning: package 'carData' was built under R version 4.5.3##
## Attaching package: 'car'## The following object is masked from 'package:psych':
##
## logit## The following object is masked from 'package:dplyr':
##
## recode## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 3 12.927 3.842e-08 ***
## 493
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Berdasarkan output di atas maka nilai p-value kurang dari taraf signifikansi (\(\alpha\)) 0.05. Hal ini berarti bahwa terdapat perbedaan varians skor FCI antara keempat sekolah secara statistik dan asumsi homogenitas dilanggar.
ANOVA juga mengasumsikan normalitas data. Kita bisa melakukan visualisasi plot Q-Q.
Contoh:
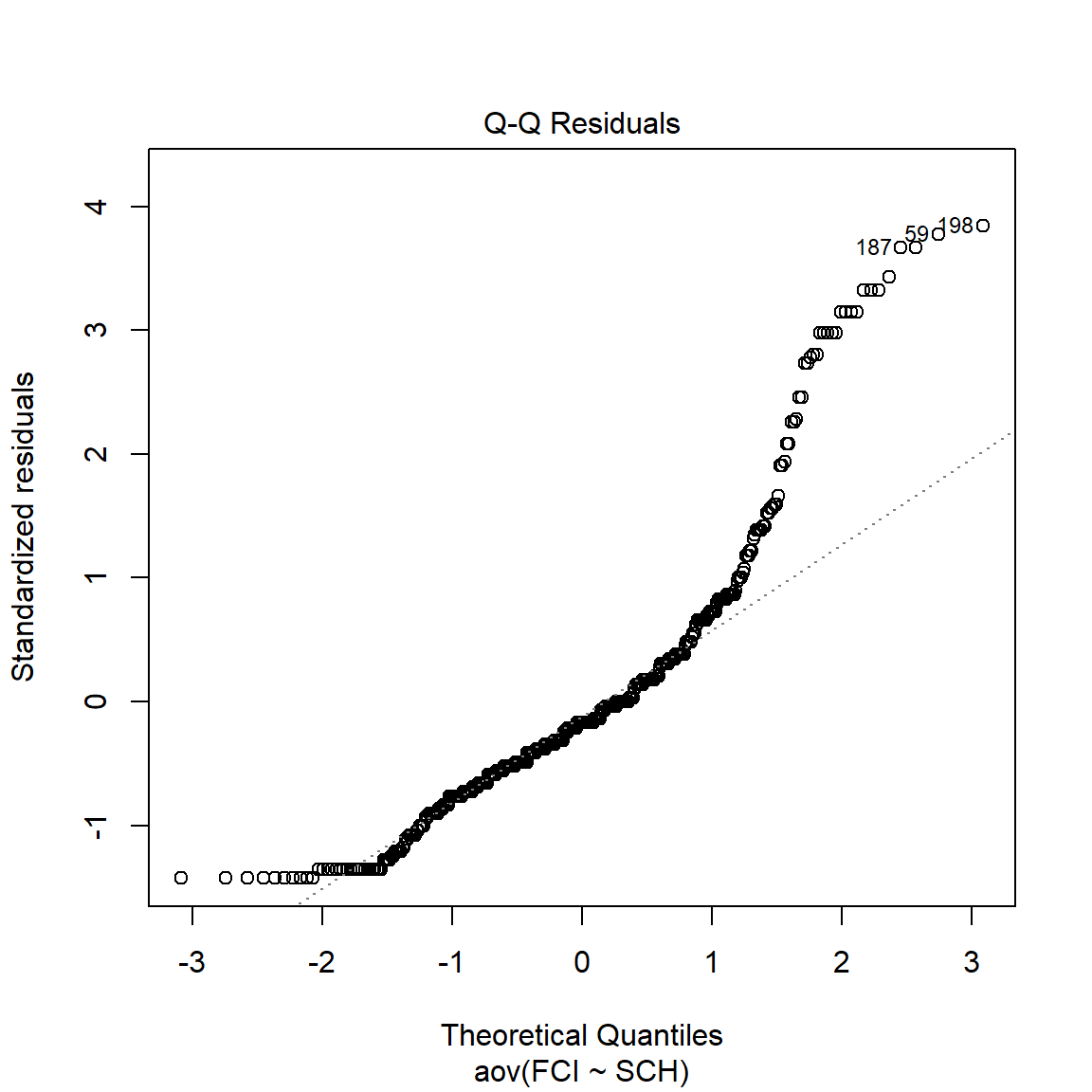
Tampak pada plot di atas adalah nilai titik-titik data residual tidak berada pada garis referensi terutama untuk nilai quantil teoretik pada kelompok siswa tinggi (sebelah kanan), hal ini menunjukkan indikasi dari dilanggarnya asumsi normalitas. Atau kita bisa mengujinya dengan uji normalitas Shapiro-Wilk.
Contoh:
##
## Shapiro-Wilk normality test
##
## data: aov_residuals
## W = 0.87301, p-value < 2.2e-16Normalitas terpenuhi jika uji Shapiro-Wilk menunjukkan nilai p-value (\(\alpha\)) yang lebih besar dari 0.05. Hasil kita menemukan nilai yang sebaliknya dan asumsi normalitas dilanggar dan seharusnya kita menggunakan statistika nonparametrik untuk lebih tepatnya.
Two Way Analysis of Variance (ANOVA)
ANOVA dua jalur (two way) menguji perbedaan antara kelompok yang dibentuk oleh dua variabel kategorik misalnya adalah SCH dan GDR. Karena terdapat 4 kategori dari variabel SCH dan 2 kategori untuk variabel GDR maka kita memiliki sebanyak 4x2 kelompok yang akan dibandingkan.
Contoh:
## Df Sum Sq Mean Sq F value Pr(>F)
## SCH 1 115 115.29 3.450 0.0638 .
## GDR 1 29 29.26 0.876 0.3498
## SCH:GDR 1 43 42.99 1.287 0.2572
## Residuals 493 16474 33.42
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Analysis of Covariance (ANCOVA)
Misalkan disini kita mengasumsikan bahwa skor FCI bisa dipengaruhi oleh kemampuan siswa pada instrumen lain seperti FMCE. Jadi FMCE dianggap sebagai “kovariat” yang mempengaruhi perbedaan skor FCI antara keempat sekolah. Untuk tujuan analisis ini maka kita harus menggunakan analysis of covariance (ANCOVA). Perlu diingat bahwa kovariat harus merupakan variabel kontinyu.
Contoh:
## Df Sum Sq Mean Sq F value Pr(>F)
## SCH 1 115 115.3 3.515 0.0614 .
## FMCE 1 343 343.3 10.468 0.0013 **
## Residuals 494 16203 32.8
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Nilai p-value lebih besar dari taraf signifikansi (\(\alpha\)) 0.05 artinya penambahan kovariat FMCE tidak terlalu berpengaruh dalam membedakan skor FCI antara keempat sekolah.
Korelasi Product-Moment (Pearson)
Korelasi Pearson mengukur hubungan linear antara dua variabel kontinyu (interval). Uji korelasi dapat kita lakukan dengan fungsi cor.test().
Contoh:
##
## Pearson's product-moment correlation
##
## data: df$FCI and df$FMCE
## t = 3.6745, df = 495, p-value = 0.0002643
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.0760862 0.2473606
## sample estimates:
## cor
## 0.1629508Signifikansi dari nilai korelasi sebesar 0.16295… diuji menggunakan statistik t dan kita lihat bahwa nilainya kurang dari taraf signifikansi (\(\alpha\)) 0.05 yang artinya bahwa nilai korelasi ini adalah signifikan secara statistik. Korelasi Pearson mengasumsikan normalitas data karena merupakan teknik statistika parametrik. Untuk alternatif data tidak normal kita bisa menggunakan korelasi Spearman (\(\rho\)) atau Kendall (\(\tau\)) yang akan dijelaskan berikutnya.
11.3 Statistika Nonparametrik dengan R
Ketika data kita tidak memenuhi asumsi normalitas maka teknik statistika yang lebih tepat adalah uji nonparametrik.
Uji Wilcoxon Satu Sampel
Sama seperti uji t satu sampel, kita mempunyai alternatif metode nonparametrik untuk tujuan yang sama yaitu dengan uji Wilcoxon satu sampel. Analisis ini dilakukan dengan fungsi wilcox.test().
Contoh:
##
## Wilcoxon signed rank test with continuity correction
##
## data: df$FCI
## V = 24346, p-value < 2.2e-16
## alternative hypothesis: true location is not equal to 10Uji Wilcoxon Signed-Rank
Alternatif dari uji t berpasangan untuk statistika nonparametrik dapat dilakukan dengan Uji Wilcoxon Signed-Rank.
Sebelumnya kita pernah menganalisis perbedaan data pretest dan postest dari skor FCI yang diuji dengan uji t berpasangan. Sekarang kita analisis dengan pendekatan statistika non parametrik.
Contoh:
##
## Wilcoxon signed rank test with continuity correction
##
## data: pretest_FCI and postest_FCI
## V = 0, p-value < 2.2e-16
## alternative hypothesis: true location shift is not equal to 0Uji Mann-Whitney U
Alternatif dari uji t dua sampel independen adalah dengan uji Mann-Whitney U melalui statistika nonparametrik.
Contoh:
Kita ulang perbandingan yang pernah kita lakukan di atas dengan pendekatan statistika nonparametrik berikut ini.
df_sekolah1 <- subset(df, SCH == 1)
df_sekolah4 <- subset(df, SCH == 4)
wilcox.test(df_sekolah1$FCI, df_sekolah4$FCI)##
## Wilcoxon rank sum test with continuity correction
##
## data: df_sekolah1$FCI and df_sekolah4$FCI
## W = 11088, p-value = 0.1773
## alternative hypothesis: true location shift is not equal to 0Uji Kruskal Wallis
Jika perbandingan kelompok dilakukan terhadap lebih dari 2 kelompok maka kita menggunakan uji kruskal wallis melalui pendekatan statistika non parametrik.
Contoh:
##
## Kruskal-Wallis rank sum test
##
## data: FCI by SCH
## Kruskal-Wallis chi-squared = 20.018, df = 3, p-value = 0.0001683Korelasi Spearman \(\rho\)
Contoh:
## Warning in cor.test.default(df$FCI, df$FMCE, method = c("spearman")): Cannot
## compute exact p-value with ties##
## Spearman's rank correlation rho
##
## data: df$FCI and df$FMCE
## S = 16995416, p-value = 0.0001486
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.1693547Korelasi Kendall \(\tau\)
Contoh:
##
## Kendall's rank correlation tau
##
## data: df$FCI and df$FMCE
## z = 3.9222, p-value = 8.776e-05
## alternative hypothesis: true tau is not equal to 0
## sample estimates:
## tau
## 0.1245448Ukuran Asosiasi Non Parametrik dengan Statistik Chi-Square
Berikut ini adalah pengujian hubungan (asosiasi) antara dua variabel kategorik dengan metode chi-square. Jika p-value lebih dari 0.05 artinya tidak terdapat hubungan signifikan antara kedua variabel kategorik tersebut.
Contoh:
## Number of cases in table: 497
## Number of factors: 2
## Test for independence of all factors:
## Chisq = 7.245, df = 3, p-value = 0.0645Atau kita bisa menggunakan fungsi chisq.test() seperti di bawah ini.
Contoh:
##
## Pearson's Chi-squared test
##
## data: table(df$SCH, df$GDR)
## X-squared = 7.2446, df = 3, p-value = 0.064511.4 Statistika Multivariat dengan R
Multivariate Analysis of Variance (MANOVA)
## Df Pillai approx F num Df den Df Pr(>F)
## SCH 1 0.10963 30.414 2 494 3.495e-13 ***
## Residuals 495
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Roy approx F num Df den Df Pr(>F)
## SCH 1 0.12313 30.414 2 494 3.495e-13 ***
## Residuals 495
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Wilks approx F num Df den Df Pr(>F)
## SCH 1 0.89037 30.414 2 494 3.495e-13 ***
## Residuals 495
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Hotelling-Lawley approx F num Df den Df Pr(>F)
## SCH 1 0.12313 30.414 2 494 3.495e-13 ***
## Residuals 495
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Response FCI :
## Df Sum Sq Mean Sq F value Pr(>F)
## SCH 1 115.3 115.289 3.4491 0.06388 .
## Residuals 495 16546.1 33.426
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Response FMCE :
## Df Sum Sq Mean Sq F value Pr(>F)
## SCH 1 12766 12765.8 60.395 4.519e-14 ***
## Residuals 495 104628 211.4
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Model Analisis Regresi dengan Variabel Amatan
Regresi Linear
Contoh:
##
## Call:
## lm(formula = FMCE ~ FCI, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -26.262 -10.611 -4.881 7.821 33.282
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 13.7182 1.1278 12.163 < 2e-16 ***
## FCI 0.4325 0.1177 3.675 0.000264 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 15.19 on 495 degrees of freedom
## Multiple R-squared: 0.02655, Adjusted R-squared: 0.02459
## F-statistic: 13.5 on 1 and 495 DF, p-value: 0.0002643## `geom_smooth()` using formula = 'y ~ x'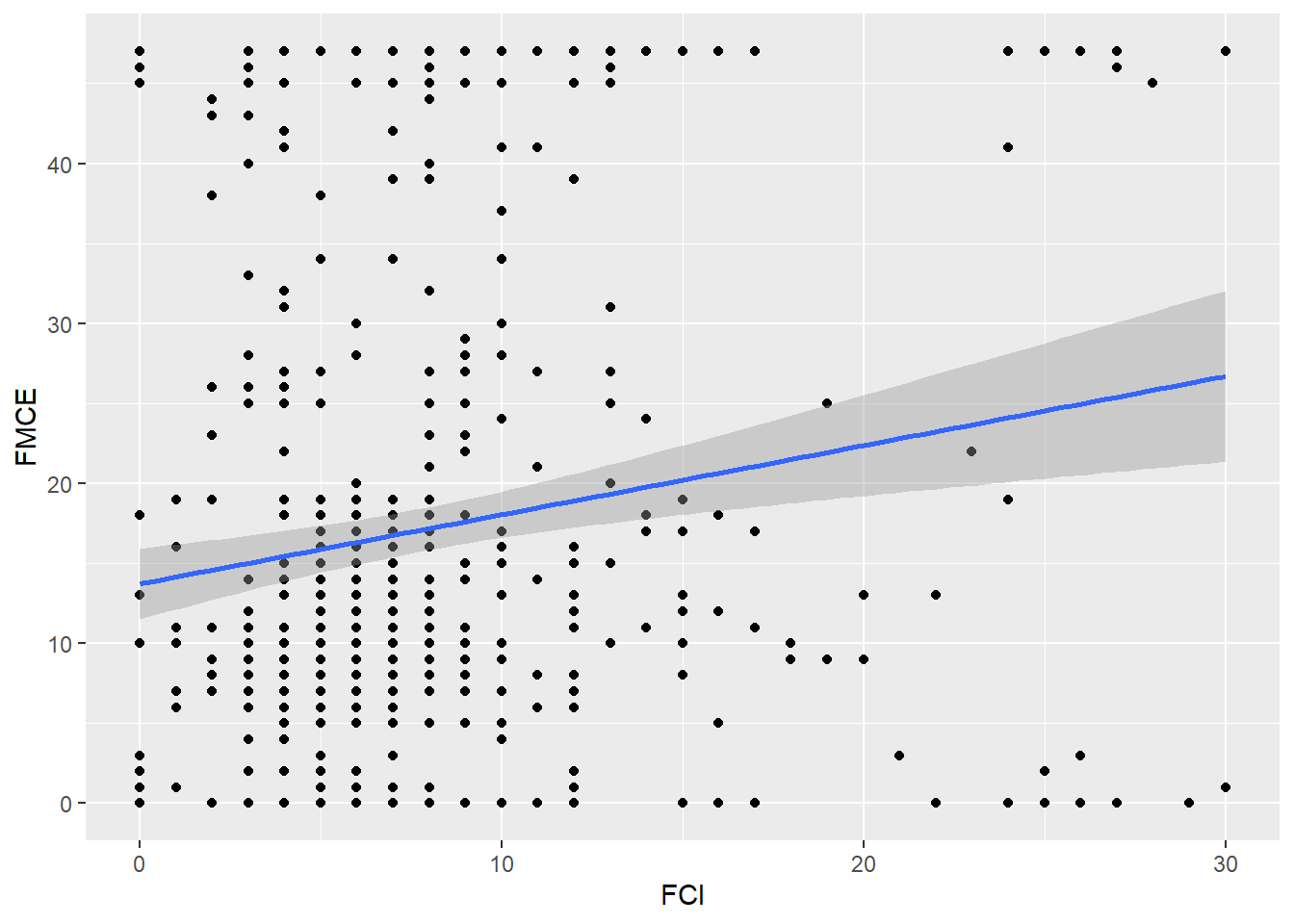
Regresi Majemuk
Contoh:
##
## Call:
## lm(formula = FINTEST2 ~ FCI + FMCE, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -58.427 -15.793 -0.606 19.285 37.897
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 55.79346 1.71457 32.541 <2e-16 ***
## FCI 0.16048 0.15915 1.008 0.314
## FMCE 0.07910 0.05996 1.319 0.188
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 20.27 on 494 degrees of freedom
## Multiple R-squared: 0.006592, Adjusted R-squared: 0.00257
## F-statistic: 1.639 on 2 and 494 DF, p-value: 0.1952Analisis Jalur
## Warning: package 'lavaan' was built under R version 4.5.3## This is lavaan 0.6-21
## lavaan is FREE software! Please report any bugs.##
## Attaching package: 'lavaan'## The following object is masked from 'package:psych':
##
## cor2covspecmod <- "
FINTEST2 ~ FCI + FMCE
FCI ~ SAAR + CLASS
FCI ~~ FMCE
"
fitmod <- sem(specmod, data = df)
summary(fitmod, standardized = TRUE, fit.measures = TRUE)## lavaan 0.6-21 ended normally after 24 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 8
##
## Number of observations 497
##
## Model Test User Model:
##
## Test statistic 96.550
## Degrees of freedom 4
## P-value (Chi-square) 0.000
##
## Model Test Baseline Model:
##
## Test statistic 123.183
## Degrees of freedom 9
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 0.189
## Tucker-Lewis Index (TLI) -0.824
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -5828.721
## Loglikelihood unrestricted model (H1) -5780.446
##
## Akaike (AIC) 11673.442
## Bayesian (BIC) 11707.111
## Sample-size adjusted Bayesian (SABIC) 11681.719
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.216
## 90 Percent confidence interval - lower 0.180
## 90 Percent confidence interval - upper 0.254
## P-value H_0: RMSEA <= 0.050 0.000
## P-value H_0: RMSEA >= 0.080 1.000
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.122
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## FINTEST2 ~
## FCI 0.160 0.159 1.012 0.312 0.160 0.046
## FMCE 0.079 0.060 1.328 0.184 0.079 0.060
## FCI ~
## SAAR -0.007 0.030 -0.244 0.808 -0.007 -0.011
## CLASS 0.052 0.016 3.187 0.001 0.052 0.144
##
## Covariances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .FCI ~~
## FMCE 12.339 3.977 3.103 0.002 12.339 0.141
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .FINTEST2 408.301 25.901 15.764 0.000 408.301 0.994
## .FCI 32.630 2.070 15.764 0.000 32.630 0.980
## FMCE 236.205 14.984 15.764 0.000 236.205 1.000Model Analisis Regresi dengan Variabel Laten
Analisis Faktor, Structural Equation Modeling (SEM)
Model Analisis Klasifikasi
Regresi Logistik, Analisis Diskriminan
Machine Learning
Merupakan salah satu metode yang berkembang hingga saat ini di bidang pendidikan. Terutama dalam riset Educational Data Mining (EDM) dan Learning Analytics (LA) (Romero & Ventura, 2020).
Unsupervised: Analisis Klaster, Principal Component Analysis (PCA)
Supervised: Regresi, K-Nearest Neighbor, Support Vector Machine, Naive Bayes, Decision Tree, Random Forest, Neural Network
11.7 Tugas (Project-Based Learning)
Tugas ini adalah proyek akhir yang dikerjakan sebagai Ujian Akhir Semester (UAS). Soalnya adalah pilihlah salah SATU teknik analisis data yang mungkin dan bisa kamu terapkan untuk mengeksplorasi dataset “spheredata” dengan R (Santoso et al., 2025). Jelaskan latar belakang mengapa kamu tertarik untuk menggunakan teknik analisis data itu dalam konteks pendidikan fisika. Kaitkan penjelasan dengan perkembangan (state of the art) hasil penelitian sebelumnya dalam bidang ilmu pendidikan fisika. Tuliskan hasil analisis ini sebagai sebuah “artikel” utuh yang terdiri dari bagian Title, Abstract, Introduction, Literature Review, Method, Results, Discussion, & Conclusion.
Untuk diperhatikan seksama, pekerjaan bisa dikumpulkan dalam bentuk artikel yang disubmit pada salah satu jurnal yang direkomendasikan di bawah ini atau jurnal lainnya yang diinginkan (ini bersifat opsional). Jika berkenan submit di jurnal, maka bukti submission (screenshot) diupload bersama dengan manuskrip artikel dalam format PDF di Google Classroom. Karena format ini bersifat opsional, maka jika ada mahasiswa yang tidak berkenan disubmit ke jurnal, maka dipersilahkan cukup hanya mengirimkan manuskrip dalam bentuk PDF di Google Classroom. Tidak ada perbedaan hasil penilaian antara keduanya.
- Physical Review Physics Education Research (https://journals.aps.org/prper/)
- Physics Education (https://iopscience.iop.org/journal/0031-9120)
- European Journal of Physics (https://iopscience.iop.org/journal/0143-0807)
- The Physics Teacher (https://pubs.aip.org/aapt/pte)
- American Journal of Physics (https://pubs.aip.org/aapt/ajp)
11.8 Rubrik Penilaian Pembelajaran
Nama Mahasiswa : NIM :
| Aspek | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Aktivitas pemrograman | … | … | … | … |
| Kelancaran tugas | … | … | … | … |
| Kualitas pekerjaan | … | … | … | … |
| Keterbukaan masukan | … | … | … | … |
Definisi
- Aktivitas pemrograman mengukur keterlibatan mahasiswa dalam proses mengikuti pelajaran.
- Kelancaran tugas mengukur sejauh mana mahasiswa mampu mengikuti prosedur pemrograman yang telah dicontohkan dalam buku ini.
- Kualitas pekerjaan mengukur kemampuan mahasiswa dalam menggunakan komputernya untuk melakukan pemrograman dengan R.
- Keterbukaan masukan mengukur sejauh mana kualitas presentasi mahasiswa dan menerima masukan dan tanggapan dari temannya yang lain.
11.9 Penutup
Ini merupakan bab terakhir dari buku ini. Kita telah banyak mendiskusikan penerapan R untuk beberapa teknik statistika dasar seperti inferensial parametrik/ nonparametrik, model analisis multivariat, machine learning, hingga analisis butir menurut teori pengukuran pendidikan. Selamat kepada para pembelajar R yang sudah sampai pada tahapan ini! Tentunya kita telah memperoleh banyak pengalaman mulai dari dasar pemrograman hingga menggunakan R untuk analisis data pada bab ini. R merupakan salah satu program komputer yang sangat bermanfaat (untuk saat ini) dalam hal analisis data penelitian. Semoga apa yang sudah dipelajari dapat dikembangkan lebih lanjut melalui pembelajaran mandiri. R memiliki banyak perkembangan setiap harinya dan kita tidak akan habisnya untuk mengeksplorasi R termasuk beberapa R package yang akan selalu diupdate secara berkala di masa depan. Yang terpenting adalah kita harus tidak pernah lelah untuk belajar. Semoga sukses untuk perjalanan R kamu di kesempatan lain!