Bab 9 Statistika Dasar dengan R
9.1 Tujuan Pembelajaran
CPMK 9
Mahasiswa mampu menerapkan keterampilan pemrograman R untuk analisis statistika dasar.
Sub-CPMK 9
Mahasiswa mampu menganalisis teknik dalam statistika deskriptif dengan menggunakan R.
Deskripsi Isi Bahan Ajar
Bab 9 ini membahas tentang:
- Pendahuluan Statistika
- Package spheredata
- Tendensi Sentral (Mean, Median, Modus)
- Nilai Jangkauan (Maksimum dan Minimum)
- Sebaran data (Varians, Standar Deviasi, Kuartil)
- Fungsi untuk Eksplorasi Statistika Deskriptif
Waktu Pembelajaran
Alokasi Waktu = 3 x 50 menit (3 SKS)
| Kegiatan | Alokasi Waktu |
|---|---|
| Ceramah dan Diskusi Interaktif | 50 menit |
| Praktik Statistika Dasar pada R | 50 menit |
| Konsultasi Praktik R | 50 menit |
| Presentasi individu | 50 menit |
Petunjuk Penggunaan Bahan Ajar
Langkah-langkah pembelajaran.
Eksplorasi package “spheredata”, analisis tendensi sentral, tentukan nilai jangkauan, pelajari sebaran data, dan mengetahui fungsi statistika dasar. Terapkan pengetahuan Anda pada contoh-contoh kasus yang telah disajikan secara individu kolaboratif. Konsultasikanlah kesulitan Anda selama praktik pada pengajar mata kuliah ini. Anda bisa bekerja dengan IDE RStudio secara offline maupun online.Sumber Belajar yang Dibutuhkan.
Laptop (Notebook), jaringan internet
Tujuan Akhir (Performance Objective)
Setelah menyelesaikan modul ini, mahasiswa mampu memahami analisis eksplorasi data penelitian pendidikan fisika meliputi ukuran tendensi sentral, nilai jangkauan, sebaran data, dan fungsi built-in R untuk statistika deskriptif.
9.2 Pendahuluan Statistika
Statistika adalah cabang ilmu yang mempelajari cara merencanakan, mengumpulkan, menganalisis, menginterpretasikan, dan menyajikan data untuk menghasilkan informasi yang berguna dalam pengambilan keputusan. Sebagai calon pendidik (guru) fisika, kita seharusnya memiliki kemampuan dasar untuk memahami ilmu ini dalam melaksanakan penelitian pembelajaran fisika. Ketika guru melakukan pembelajaran, kita akan sering melakukan proses penilaian pembelajaran yang digunakan untuk mengevaluasi ketercapaian hasil belajar fisika. Hasil penilaian merupakan dasar pendidik dalam mengambil keputusan perlakuan pembelajaran yang tepat untuk diimplementasikan kepada peserta didik. Keputusan pembelajaran yang dibuat berbasis data seharusnya dapat meningkatkan pembelajaran individu siswa yang selanjutnya akan meningkatkan keefektifan pembelajaran pada tingkat kelas. Visi ini merupakan cikal bakal dari bidang ilmu yaitu Educational Data Mining (EDM) dan Learning Analytics (LA) yang keduanya memiliki perhatian lebih untuk mengelola data yang dihasilkan dari lingkungan pendidikan dan bagaimana data tersebut digunakan untuk mendukung proses pembelajaran khususnya pendidikan fisika (Romero & Ventura, 2020). Perhatikan gambar di bawah ini tentang visi dari EDM dan LA.
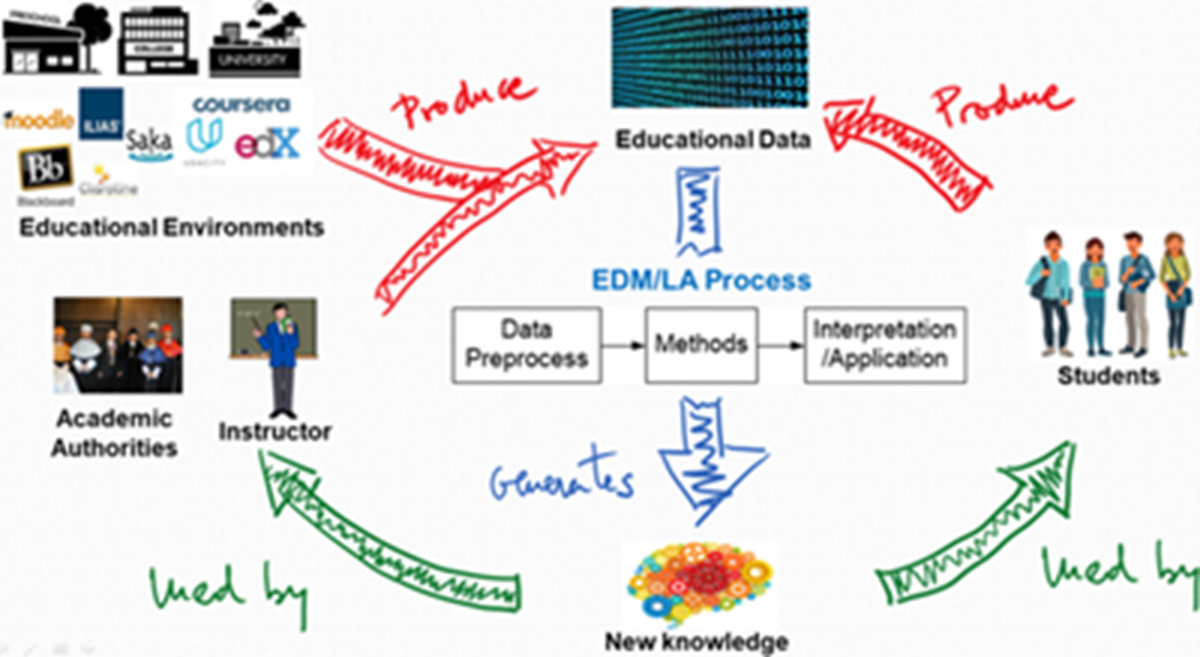
Sampai pada tingkat pendidikan sarjana, kita seharusnya telah memahami statistika dasar yang pernah dipelajari pada tingkat sekolah menengah atas (SMA). Ilmu ini akan menjadi landasan kita dalam mengksplorasi R untuk analisis data penelitian pendidikan. Sebelum kita lebih jauh dalam menyelami ilmu statistika dengan R, pada bab 9 ini kita akan sedikit mengulang kembali ilmu-ilmu yang telah kita pelajari tentang statistika dasar yang mungkin pernah kita pelajari sebelumnya yang akan kita terapkan di R.
9.3 Package spheredata
Materi untuk statistika dasar ini akan disajikan bersama dengan contoh penerapan perhitungan di R. Contoh analisis data akan dilakukan berdasarkan hasil penelitian pendidikan fisika yang dilakukan oleh peneliti sebelumnya (Santoso et al., 2025). Data penelitian ini telah disimpan dalam sebuah package yang bernama “spheredata”. Jika Anda belum pernah menginstallnya, maka Anda harus menginstallnya terlebih dahulu seperti yang pernah dijelaskan pada bab 1 dan bab 7.
Untuk mengolah data pendidikan yang dilaporkan oleh package “spheredata”, kita terlebih dahulu perlu mempelajari konteks atau isi dari data ini. Paling tidak kita mencari tahu dengan metode 5W+1H. Data ini mengukur apa? Siapa yang diukur? Dimana lokasi pengumpulan datanya? Bagaimana proses pengumpulan datanya? Kapan penilaian atau tes dilakukan? Dokumentasi dari package “spheredata” yang bisa diakses via link (https://cran.r-project.org/web/packages/spheredata/spheredata.pdf) bisa dipelajari lagi dengan seksama untuk mendalaminya lagi. Deskripsi lengkap dari data ini juga telah dilaporkan dalam sebuah artikel yang diterbitkan di jurnal Scientific Data (Santoso et al., 2025) untuk deskripsi yang lebih naratif dan lengkap. Jika Anda sudah memahami konteks dari data tersebut, kita sudah siap untuk mempelajari data tersebut pada bab 9 ini.
Sekarang kita pertama-tama akan membuat sebuah dataframe untuk menggabungkan seluruh data dari package “spheredata”. Package “spheredata” memuat data hasil penilaian terhadap siswa kelas XI pada kurikulum semester ganjil dan genap di beberapa sekolah menengah atas (SMA) dalam beberapa materi utama dalam kurikulum fisika antara lain:
- Mekanika diukur oleh Force Concept Inventory (FCI) (Hestenes et al., 1992).
- Mekanika diukur oleh Force and Motion Conceptual Evaluation (FMCE) (Thornton & Sokoloff, 1998).
- Gerak rotasi diukur oleh Rotational and Rolling Motion Conceptual Survey (RRMCS) (Rimoldini & Singh, 2005).
- Fluida dinamis diukur oleh Fluid Mechanics Concept Inventory (FMCI) (Martin et al., 2003)
- Gelombang mekanik diukur oleh Mechanical Waves Conceptual Survey (MWCS) (Barniol & Zavala, 2016).
- Kalor diukur oleh Thermal Concept Inventory (TCE) (Yeo & Zadnik, 2001).
- Termodinamika diukur oleh Survey of Thermodynamic Processes and First and Second Laws (STPFaSL) (Brown & Singh, 2021).
- Sikap siswa diukur oleh Colorado Learning Attitude about Science Survey (CLASS) (Adams et al., 2006).
- Keterampilan proses diukur oleh Scientific Abilities Assessment Rubric (SAAR) (Etkina et al., 2006).
Jika Anda tertarik untuk mempelajari butir-butir tes dari semua instrumen tersebut bisa membaca artikel-artikel yang pernah dikutip di atas. Untuk mengakses butir soal dari instrumen tersebut, Anda bisa menghubungi guru atau dosen Anda yang telah terdaftar sebagai akun pendidik melalui platform PhysPort (https://www.physport.org/assessments/).
Contoh:
library(spheredata)
skorFCI <- rowSums(binary(FCI, FCIkey))
skorFMCE <- rowSums(binary(FMCE, FMCEkey))
skorRRMCS <- rowSums(binary(RRMCS, RRMCSkey))
skorFMCI <- rowSums(binary(FMCI, FMCIkey))
skorMWCS <- rowSums(binary(MWCS, MWCSkey))
skorTCE <- rowSums(binary(TCE, TCEkey))
skorSTPFASL <- rowSums(binary(STPFASL, STPFASLkey))
skorCLASS <- rowSums(CLASS)
skorSAAR <- rowSums(SAAR)
df <- data.frame(demographic,
FCI = skorFCI,
FMCE = skorFMCE,
RRMCS = skorRRMCS,
FMCI = skorFMCI,
MWCS = skorTCE,
TCE = skorTCE,
STPFASL = skorSTPFASL,
CLASS = skorCLASS,
SAAR = skorSAAR)
head(df)## STUDID SCH COH GDR AGE FATHOCC MOTHOCC FATHEDU MOTHEDU FATHINC MOTHINC SIBL
## 1 A1001 1 1 1 3 1 9 4 5 7 12 2
## 2 A1002 1 1 2 1 4 8 4 4 10 12 2
## 3 A1003 1 1 1 2 4 8 3 4 2 12 0
## 4 A1004 1 1 2 3 1 1 2 2 6 6 3
## 5 A1005 1 1 1 2 1 1 3 3 10 10 2
## 6 A1006 1 1 2 2 1 7 4 2 9 4 2
## DOM FCI FMCE RRMCS FMCI MWCS TCE STPFASL CLASS SAAR
## 1 1 6 30 15 0 14 14 22 135 46
## 2 1 10 15 23 13 8 8 12 120 51
## 3 1 10 45 10 11 18 18 15 121 47
## 4 1 4 45 9 11 16 16 15 105 45
## 5 1 2 23 18 0 8 8 1 106 34
## 6 2 7 0 4 0 10 10 9 84 39## 'data.frame': 497 obs. of 22 variables:
## $ STUDID : chr "A1001" "A1002" "A1003" "A1004" ...
## $ SCH : num 1 1 1 1 1 1 1 1 1 1 ...
## $ COH : num 1 1 1 1 1 1 1 1 1 1 ...
## $ GDR : num 1 2 1 2 1 2 2 2 2 2 ...
## $ AGE : num 3 1 2 3 2 2 2 2 2 2 ...
## $ FATHOCC: num 1 4 4 1 1 1 1 4 1 2 ...
## $ MOTHOCC: num 9 8 8 1 1 7 1 5 1 2 ...
## $ FATHEDU: num 4 4 3 2 3 4 4 2 4 4 ...
## $ MOTHEDU: num 5 4 4 2 3 2 3 1 3 4 ...
## $ FATHINC: num 7 10 2 6 10 9 8 10 10 11 ...
## $ MOTHINC: num 12 12 12 6 10 4 8 5 9 11 ...
## $ SIBL : num 2 2 0 3 2 2 2 2 1 2 ...
## $ DOM : num 1 1 1 1 1 2 2 1 1 1 ...
## $ FCI : num 6 10 10 4 2 7 9 4 6 7 ...
## $ FMCE : num 30 15 45 45 23 0 47 47 47 39 ...
## $ RRMCS : num 15 23 10 9 18 4 13 14 11 15 ...
## $ FMCI : num 0 13 11 11 0 0 12 12 6 0 ...
## $ MWCS : num 14 8 18 16 8 10 17 18 12 18 ...
## $ TCE : num 14 8 18 16 8 10 17 18 12 18 ...
## $ STPFASL: num 22 12 15 15 1 9 13 15 13 15 ...
## $ CLASS : num 135 120 121 105 106 84 127 128 124 123 ...
## $ SAAR : num 46 51 47 45 34 39 50 48 49 47 ...Berikut ini adalah deskripsi singkat dari setiap kolom (variabel) dari dataset “spheredata”. Untuk lebih lengkapnya bisa ditelusuri lebih lanjut pada publikasi (Santoso et al., 2025).
| Nama variabel | Deskripsi |
|---|---|
| STUDID | Identitas siswa dengan kode unik. |
| SCH | Identitas sekolah. 1 adalah sekolah A, 2 adalah sekolah B, dst. |
| COH | Identitas kelas dari setiap sekolah. 1 adalah kelas A, 2 adalah kelas B, dst. |
| GDR | Jenis kelamin siswa. 1 adalah laki-laki. 2 adalah perempuan. |
| AGE | Umur |
| FATHOCC | Pekerjaan bapak |
| MOTHOCC | Pekerjaan ibu |
| FATHEDU | Pendidikan bapak |
| MOTHHEDU | Pendidikan ibu |
| FATHINC | Penghasilan bapak |
| MOTHINC | Penghasilan ibu |
| SIBL | Jumlah saudara |
| DOM | Asal domisili |
| FCI | Skor FCI |
| FMCE | Skor FMCE |
| RRMCS | Skor RRMCS |
| FMCI | Skor FMCI |
| MWCS | Skor MWCS |
| TCE | Skor TCE |
| STPFASL | Skor STPFASL |
| CLASS | Skor CLASS |
| SAAR | Skor SAAR |
Fungsi table() dapat kita gunakan untuk mempelajari distribusi dari setiap kelas di dalam data kategorik. Contohnya disini kita ingin mencari berapa jumlah siswa dalam setiap sekolah.
Contoh:
Terdapat 143 siswa di sekolah 1, 141 siswa di sekolah 2, 71 siswa di sekolah 3, dan 142 siswa di sekolah 4.
##
## 1 2 3 4
## 143 141 71 142Sekarang kita sedang mengeskplorasi data jumlah siswa dari setiap kelas dari suatu sekolah.
Contoh:
##
## 1 2 3 4
## 36 36 36 35Atau kita bisa menggunakan metode yang lebih canggih yaitu dengan package “dplyr”. Jika kamu belum menginstallnya maka harus diinstall terlebih dahulu.
## Warning: package 'dplyr' was built under R version 4.5.3##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union## COH n
## 1 1 36
## 2 2 36
## 3 3 36
## 4 4 35Dengan fungsi table() kita bisa membuat tabel kontingensi antara 2 variabel kategorik. Dalam contoh di bawah ini, kita sedang mempelajari bagaimana sebaran jenis kelamin siswa pada setiap sekolah. Angka 1 adalah laki-laki dan 2 adalah siswa perempuan.
Contoh:
##
## 1 2
## 1 62 81
## 2 64 77
## 3 24 47
## 4 75 67Berikut ini adalah tabel distribusi frekuensi (dalam proporsi) atau conditional distribution untuk kolom sekolah vs pekerjaan ayah.
Contoh:
##
## 1 2 3 4 5 6
## 1 0.363636364 0.055944056 0.076923077 0.104895105 0.034965035 0.020979021
## 2 0.241134752 0.092198582 0.085106383 0.241134752 0.035460993 0.007092199
## 3 0.239436620 0.225352113 0.070422535 0.112676056 0.028169014 0.000000000
## 4 0.338028169 0.084507042 0.063380282 0.176056338 0.014084507 0.000000000
##
## 7 8 9
## 1 0.125874126 0.048951049 0.167832168
## 2 0.056737589 0.028368794 0.212765957
## 3 0.042253521 0.000000000 0.281690141
## 4 0.112676056 0.014084507 0.1971830999.4 Tendensi Sentral (Mean, Median, Modus)
Jika kita memiliki data \(X_1, X_2, ..., X_N\), maka nilai rerata dapat dicari sebagai berikut.
\[ \overline{X} = \frac{1}{N} \sum_{i=1}^{N} x_i \]
Jika kita ingin menghitung rerata dari skor FCI dalam data kita. R sudah memberikan fungsi bawaan secara mudah sebagai berikut.
Contoh:
## [1] 7.633803Nilai median adalah nilai tengah dari data setelah data diurutkan dari terkecil hingga terbesar. R juga sudah memberikan fasilitas fungsi bawaan untuk menghitung median dari data kita dengan cara sebagai berikut.
Contoh:
## [1] 6Kita juga bisa mencari median melalui kuartil 2 (Q2) dengan cara sebagai berikut.
## 50%
## 6Modus adalah nilai terbanyak yang terjadi di dalam data kita. Akan tetapi R tidak menyediakan fungsi instan untuk menghitung nilai modus. Kita harus membuat fungsi baru untuk menghitung modus tersebut dengan cara sebagai berikut.
Contoh:
hitung_modus <- function(x) {
uniqv <- unique(x)
uniqv[which.max(tabulate(match(x, uniqv)))]
}
hitung_modus(df$FCI)## [1] 6Sekarang apakah kalian bisa membuat sebuah fungsi sendiri dalam menghitung mean dan median dari data dengan R? Ayo praktik!
9.5 Nilai Jangkauan (Maksimum dan Minimum)
Fungsi max() dapat kita gunakan untuk mencari nilai tertinggi (maksimum) dari data kita.
Contoh:
## [1] 30Fungsi min() dapat kita gunakan untuk mencari nilai terkecil (minimum) dari data kita.
Contoh:
## [1] 0Jangkauan (range) adalah nilai tertinggi dikurangi nilai terkecil.
Contoh:
## [1] 30Atau kita bisa mencari jangkauan dengan menggunakan fungsi range() sebagai berikut.
## [1] 0 30Mencari kuartil
Contoh:
## 25%
## 4## 75%
## 10Mencari desil dan persentil
Contoh:
## 40%
## 6## 98%
## 26Jarak interkuartil (Q3-Q1) dapat dihitung melalui fungsi bawaan sebagai berikut.
Contoh:
## [1] 69.6 Sebaran data (Varians, Standar Deviasi, Kuartil)
Standar deviasi (simpangan baku) adalah ukuran sejauh mana data kita menyimpang dari nilai rata-ratanya. Nilai standar deviasi dapat dicari dengan formulasi sebagai berikut.
\[ SD=\sqrt{\sum_{i=1}^{N} \frac{(X_i-\overline{X})^2}{N}} \]
## [1] 5.795812Varians adalah kuadrat dari standar deviasi.
## [1] 33.59144Apakah kamu bisa membuat fungsi R sendiri untuk menghitung standar deviasi dan varians dari data? Ayo praktik!
9.7 Fungsi untuk Eksplorasi Statistika Deskriptif
Pada bagian sebelumnya, kita sudah mencari nilai mean, median, modus, kuartil dengan menggunakan fungsi bawaan atau fungsi yang kita buat sendiri. R sebenarnya juga telah menyediakan fasilitas instan untuk mendeskripsikan data dengan fungsi summary().
Contoh:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.000 4.000 6.000 7.634 10.000 30.000Fungsi summary() merupakan fitur bawaan yang disediakan oleh R. Meskipun demikian, fungsi ini masih memiliki keterbatasan informasi statistik yang bisa disajikan. Salah satu package yang memberikan informasi statistika deskriptif secara lebih lengkap difasilitasi oleh package “psych” dengan fungsi describe() (nama fungsi ini sama persis untuk melakukan statistika deskriptif di bahasa pemrograman lain seperti di Python). Untuk menggunakan package “psych”, kita perlu menginstallnya terlebih dahulu dan memanggilnya dengan fungsi library(package_name) untuk mengaktifkannya dalam lingkungan kerja kita.
## Warning: package 'psych' was built under R version 4.5.3## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 497 7.63 5.8 6 6.86 4.45 0 30 30 1.55 2.9 0.26Nilai skewness yang tidak lebih dari 2 (positif atau negatif) dan kurtosis yang tidak lebih dari 7 (positif atau negatif) menunjukkan data berdistribusi normal (memenuhi asumsi normalitas data).
Untuk mengubah nilai data kita ke dalam distribusi normal kita bisa menggunakan nilai z. Nilai standar z akan memiliki nilai rata-rata sebesar nol dan standar deviasi sebesar 1.
\[ z=\frac{X-\mu}{\sigma} \]
dimana \(X\) adalah nilai data, \(\mu\) adalah rata-rata populasi, dan \(\sigma\) adalah simpangan baku populasi.
Misalkan kita ingin mengetahui nilai standar dari skor FCI dalam dataset kita.
Contoh:
## [1] 7.953397e-17## [1] 1Atau kita bisa menggunakan fungsi bawaan R yang digunakan untuk mengubah data mentah ke dalam distribusi normal (z). Fungsinya adalah scale(). Apakah hasilnya sama dengan perhitungan manual di atas?!
## [1] 7.953397e-17## [1] 19.8 Tugas (Project-Based Learning)
Analisislah nilai rerata, median, modus, simpangan baku, varians, maksimum, dan minimum untuk data penilaian yang lain yaitu pada FMCE, RRMCS, FMCI, MWCS, TCE, STPFASL, CLASS, dan SAAR dan susunlah nilai deskripsi data tersebut dalam sebuah dataframe tunggal yang mudah dipresentasikan! Tuliskanlah pekerjaan Anda melalui R Notebook dan sajikanlah hasil analisis di depan teman sekelas dan pendidik pemrograman pada mata kuliah ini!
Hitunglah nilai standar z untuk skor FMCE, RRMCS, FMCI, MWCS, TCE, STPFASL, CLASS, dan SAAR!
9.9 Rubrik Penilaian Pembelajaran
Nama Mahasiswa : NIM :
| Aspek | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Aktivitas pemrograman | … | … | … | … |
| Kelancaran tugas | … | … | … | … |
| Kualitas pekerjaan | … | … | … | … |
| Keterbukaan masukan | … | … | … | … |
Definisi
- Aktivitas pemrograman mengukur keterlibatan mahasiswa dalam proses mengikuti pelajaran.
- Kelancaran tugas mengukur sejauh mana mahasiswa mampu mengikuti prosedur pemrograman yang telah dicontohkan dalam buku ini.
- Kualitas pekerjaan mengukur kemampuan mahasiswa dalam menggunakan komputernya untuk melakukan pemrograman dengan R.
- Keterbukaan masukan mengukur sejauh mana kualitas presentasi mahasiswa dan menerima masukan dan tanggapan dari temannya yang lain.
9.10 Penutup
Pada bab ini, materi statistika dasar berupa ukuran tendensi sentral, sebaran data, nilai jangkauan telah disajikan. Kita telah menerapkan R melalui package spheredata untuk mencoba melakukan analisis statistika dasar dalam meeksplorasi data hasil penilaian pendidikan fisika. Untuk selanjutnya data-data ini dapat dieksplorasi lebih lanjut melalui implementasi dari teknik-teknik analisis statistika lebih lanjut yang tentunya lebih menantang. R adalah salah satu program komputer yang sangat bermanfaat untuk mempelajari statistika untuk analisis data penelitian pendidikan.