Bab 10 Visualisasi Data dengan R
10.1 Tujuan Pembelajaran
CPMK 10
Mahasiswa mampu menerapkan keterampilan pemrograman R untuk visualisasi data penelitian pendidikan fisika.
Sub-CPMK 10
Mahasiswa mampu mengkreasi visualisasi data dengan diagram batang, scatter, line, histogram, boxplot, density, dalam R.
Deskripsi Isi Bahan Ajar
Bab 10 ini membahas tentang:
- Pendahuluan
- Visualisasi Distribusi.
- Visualisasi Asosiasi.
- Visualisasi Kategorisasi.
Waktu Pembelajaran
Alokasi Waktu = 3 x 50 menit (3 SKS)
| Kegiatan | Alokasi Waktu |
|---|---|
| Ceramah dan Diskusi Interaktif | 50 menit |
| Praktik Visualisasi Data pada R | 50 menit |
| Konsultasi Praktik R | 50 menit |
| Presentasi individu | 50 menit |
Petunjuk Penggunaan Bahan Ajar
Langkah-langkah pembelajaran.
Pelajari visualisasi distribusi, asosiasi, dan kategorisasi. Terapkan pengetahuan Anda pada contoh-contoh kasus yang telah disajikan secara individu kolaboratif. Konsultasikanlah kesulitan Anda selama praktik pada pengajar mata kuliah ini. Anda bisa bekerja dengan IDE RStudio secara offline maupun online.Sumber Belajar yang Dibutuhkan.
Laptop (Notebook), jaringan internet
Tujuan Akhir (Performance Objective)
Setelah menyelesaikan modul ini, mahasiswa mampu mengkreasi visualisasi distribusi, asosiasi, dan kategorisasi dengan R.
10.2 Pendahuluan
Pada bab sebelumnya, kita telah banyak berinteraksi dengan data. R adalah salah satu perangkat lunak pemrograman yang sering digunakan untuk analisis data penelitian. Data mentah tidak bisa menjadi informasi yang berguna ketika belum kita analisis. Salah satu cara kita untuk menghasilkan informasi yang mudah dipahami adalah melalui visualisasi. Kita bisa melihat tren, tendensi, sebaran, atau pola melalui visualisasi yang kita ciptakan. Pada bab 10 ini, kita akan mempelajari bagaimana mengolah data dan menghasilkan informasi yang berguna melalui salah satu teknik analisis yang penting yaitu visualisasi data.
10.3 Visualisasi Distribusi
Terdapat beberapa bentuk visualisasi untuk melihat distribusi data kita antara lain histogram, density plot, boxplot, dan violin plot.
Histogram
Misalkan sekarang kita ingin membuat histogram dari data skor FCI yang kita pernah olah pada spheredata. Histogram adalah suatu visualisasi untuk melihat bagaimana sebaran data kita. Kita juga bisa menilai apakah sebaran data kita berdistribusi normal atau tidak dari visualisasi histogram ini.
Contoh:
Membuat dataframe pensekoran spheredata.
library(spheredata)
skorFCI <- rowSums(binary(FCI, FCIkey))
skorFMCE <- rowSums(binary(FMCE, FMCEkey))
skorRRMCS <- rowSums(binary(RRMCS, RRMCSkey))
skorFMCI <- rowSums(binary(FMCI, FMCIkey))
skorMWCS <- rowSums(binary(MWCS, MWCSkey))
skorTCE <- rowSums(binary(TCE, TCEkey))
skorSTPFASL <- rowSums(binary(STPFASL, STPFASLkey))
skorCLASS <- rowSums(CLASS)
skorSAAR <- rowSums(SAAR)
skorUAS1 <- teachersjudgment$FINTEST1
skorUAS2 <- teachersjudgment$FINTEST2
df <- data.frame(demographic,
FCI = skorFCI,
FMCE = skorFMCE,
RRMCS = skorRRMCS,
FMCI = skorFMCI,
MWCS = skorTCE,
TCE = skorTCE,
STPFASL = skorSTPFASL,
CLASS = skorCLASS,
SAAR = skorSAAR, skorUAS1, skorUAS2)Histogram skor FCI dibuat dengan fungsi hist() yang merupakan singkatan dari “histogram”. Argumen breaks mengatur seberapa banyak data kita ingin dikelompokkan? Argumen xlab untuk menuliskan nama sumbu x. Argumen ylab untuk menuliskan nama sumbu y. Argumen main untuk menuliskan judul grafik. Argumen col untuk mengatur warna dari histogram kita. Jika melihat distribusinya apakah data skor FCI berdistribusi normal?
hist(df$FCI, breaks = 30, xlab = "Skor FCI", ylab = "Frekuensi", main = "Histogram Skor FCI", col = rgb(1,0,0,0.5))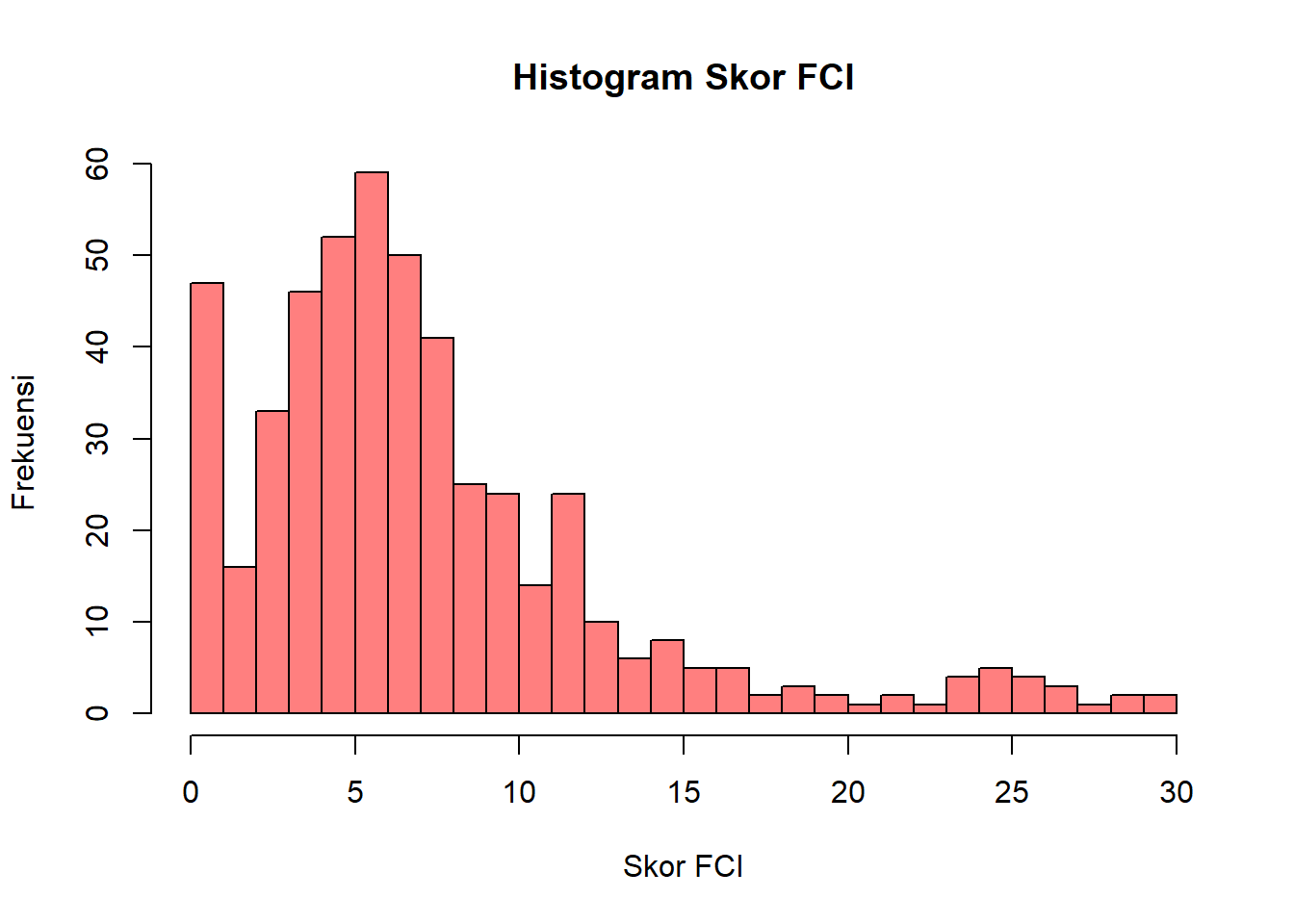
Salah satu package R yang sangat powerful untuk visualisasi data adalah “ggplot2”. Ini merupakan salah satu package yang paling banyak digunakan oleh para pengguna R untuk menghasilkan visualisasi yang indah dan mengesankan. Kita juga bisa membuat histogram dengan memanfaatkan package ini. Kamu harus menginstall package “ggplot2” jika belum pernah menginstallnya sebelumnya. Histogram dibuat dengan fungsi geom_histogram() dengan package ggplot2.
##
## Attaching package: 'ggplot2'## The following objects are masked from 'package:psych':
##
## %+%, alphaggplot(df, aes(x=FCI)) +
geom_histogram(binwidth = 1, fill=rgb(1,0,0,0.5), color="black", alpha=0.5)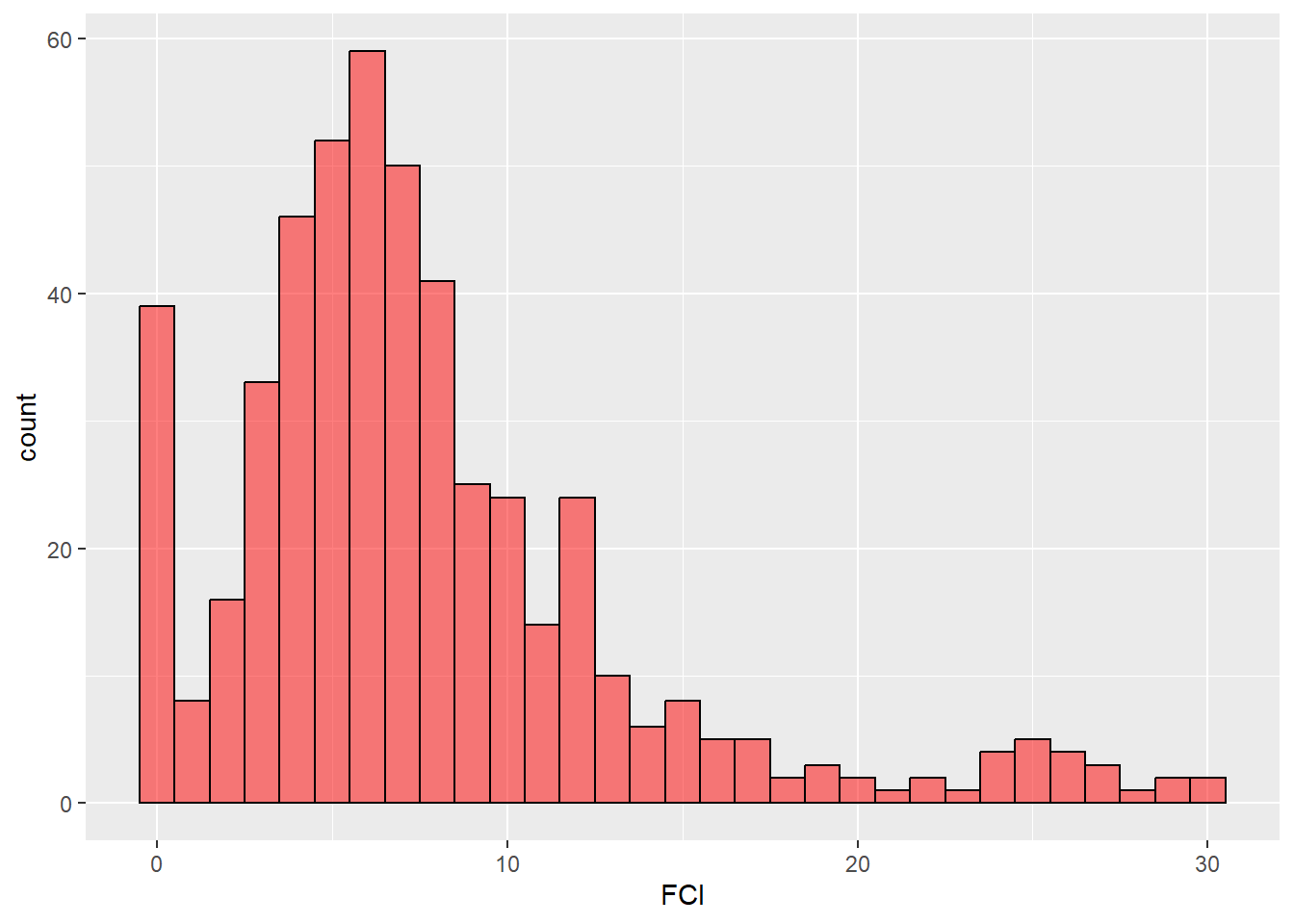
Sekarang kita ingin membuat visualisasi histogram untuk sekolah (SCH) 1. Kita akan mulai menggunakan cara kerja dengan package “dplyr” untuk membuat subset data FCI. Operator “pipe” ( |> ) adalah operator pipa yang memfilter data kita untuk observasi SCH = 1 saja. Shortcut pada keyboard bisa menggunakan tombol Ctrl+Shift+M.
library(dplyr)
df |>
filter(SCH == 1) |>
ggplot(aes(x=FCI)) +
geom_histogram(binwidth = 1, fill=rgb(1,0,0,0.5), color="black", alpha=0.5) +
ggtitle("Histogram Skor FCI dengan 'ggplot2'") +
theme(plot.title = element_text(hjust = 0.5))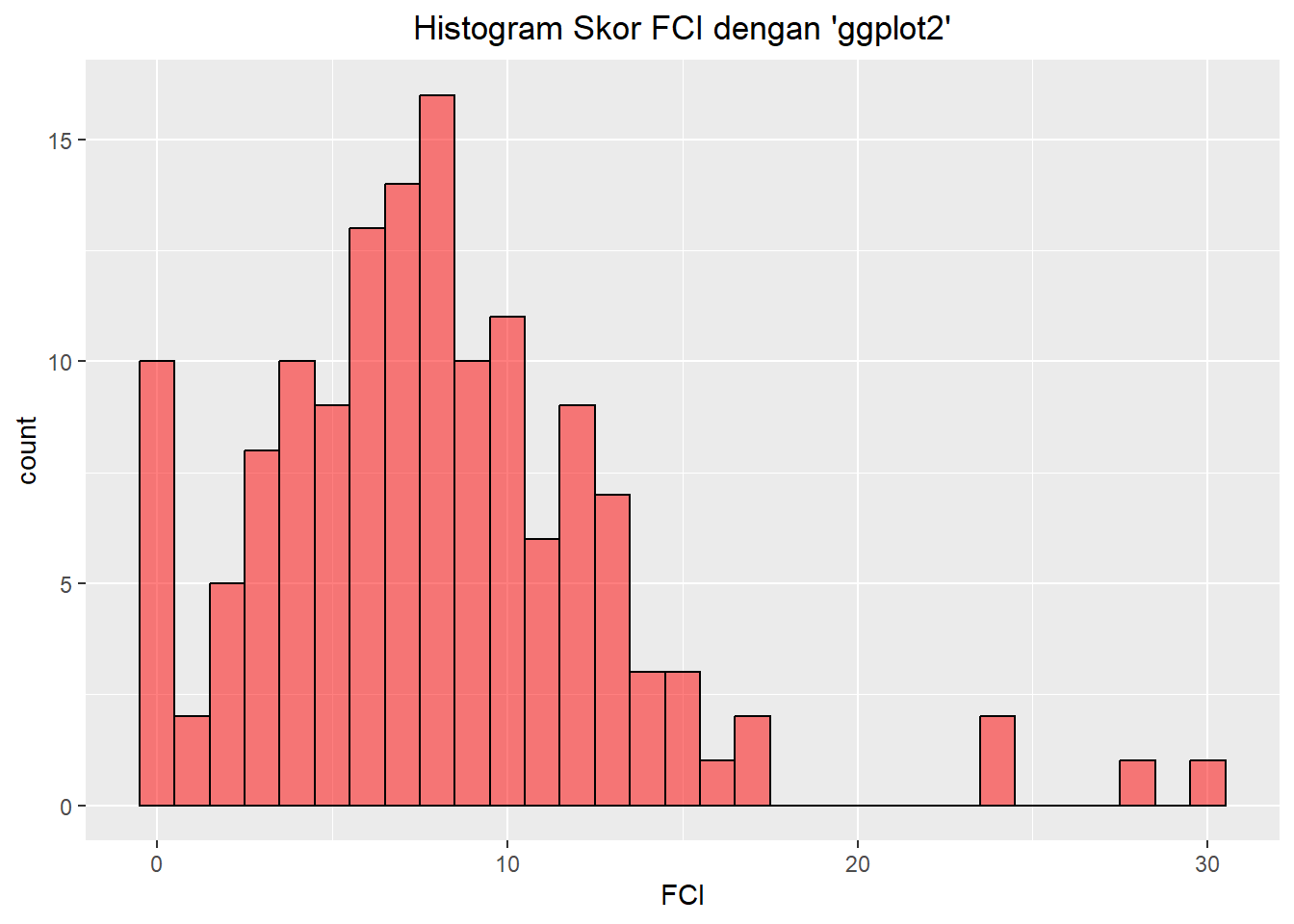
Sekarang kita ingin membuat dua histogram untuk mempelajari bagaimana distribusi skor FCI antara kelompok siswa laki-laki dengan perempuan. Apakah secara visual terdapat perbedaan signifikan?
df |>
ggplot(aes(x=FCI, fill = factor(GDR))) +
geom_histogram(binwidth = 1, color="#e9ecef", alpha=0.8, position = 'dodge') +
labs(fill="Gender", x = "Skor FCI", y = "Frekuensi") +
scale_fill_manual(values=c("blue", "red"), labels = c("Laki-laki", "Perempuan")) +
ggtitle("Histogram Skor FCI antar Gender") +
theme(plot.title = element_text(hjust = 0.5))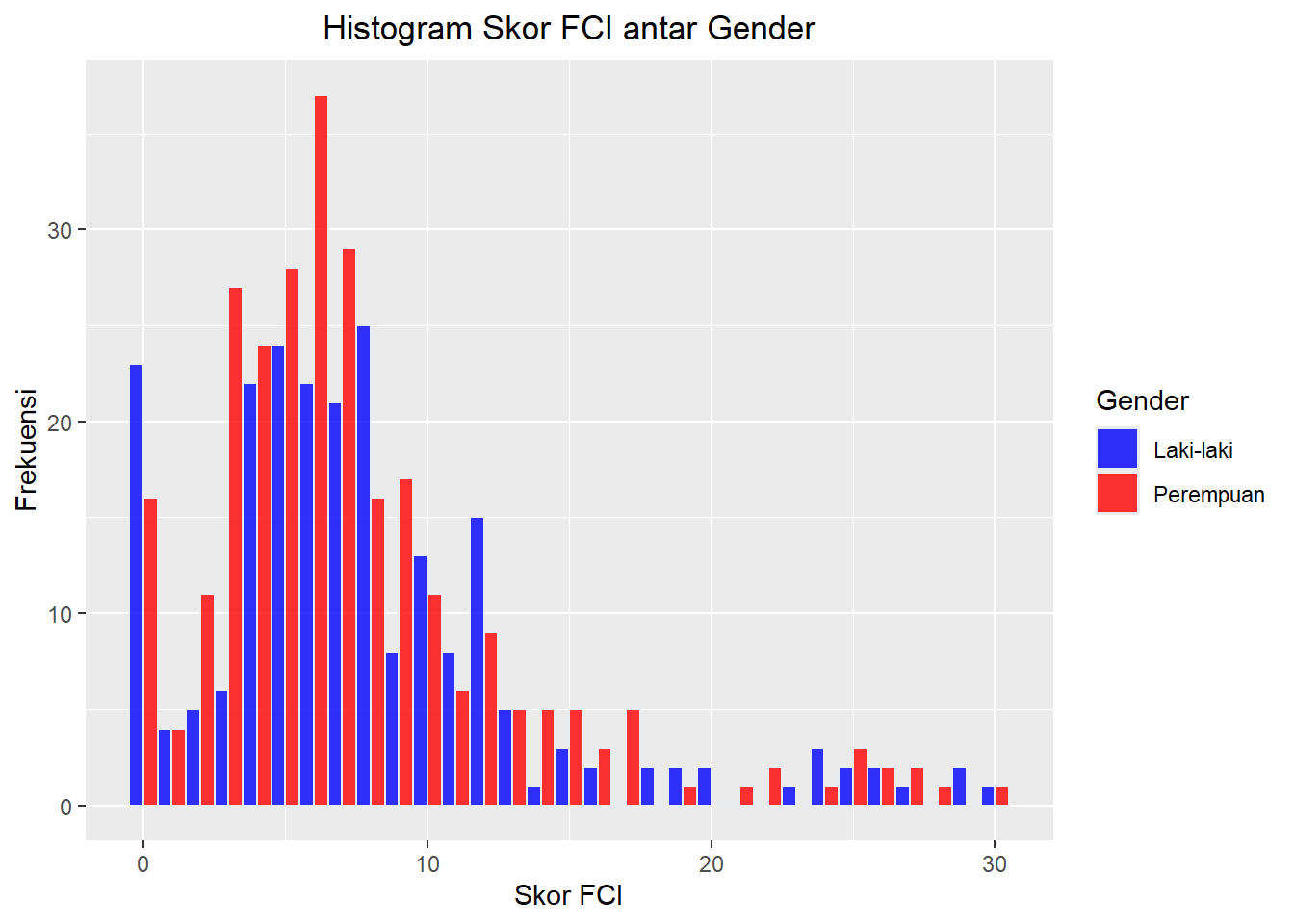
Density Plot
Jenis grafik ini mirip seperti histogram, perbedaannya adalah kurva yang dibentuk membentuk luasan di bawah kurva distribusi. Melalui ggplot2, density plot dibuat dengan fungsi geom_density(). Kita juga bisa menggunakan base R untuk membuat density plot.
Contoh:
x <- subset(df, SCH == 1)
d <- density(x$FCI)
plot(d, xlim = c(0,30), main = "Density Plot Skor FCI")
polygon(d, col = rgb(0, 0, 1, 0.3), border = "black")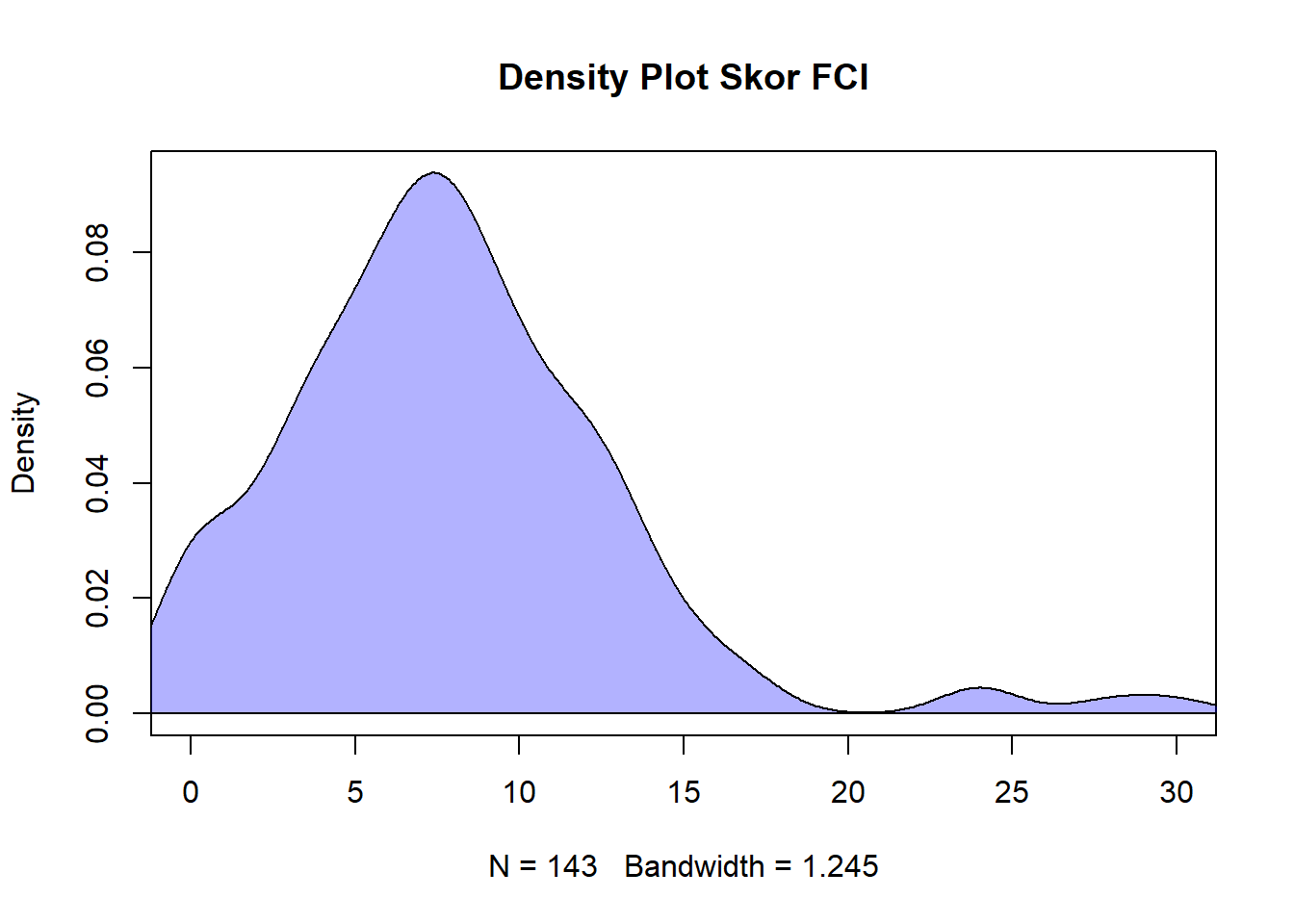
df |>
filter(SCH == 1) |>
ggplot(aes(x=FCI)) +
geom_density(fill=rgb(1,0,0,0.5), color="black", alpha=0.5) +
ggtitle("Density Plot dari Skor FCI") +
theme(plot.title = element_text(hjust = 0.5))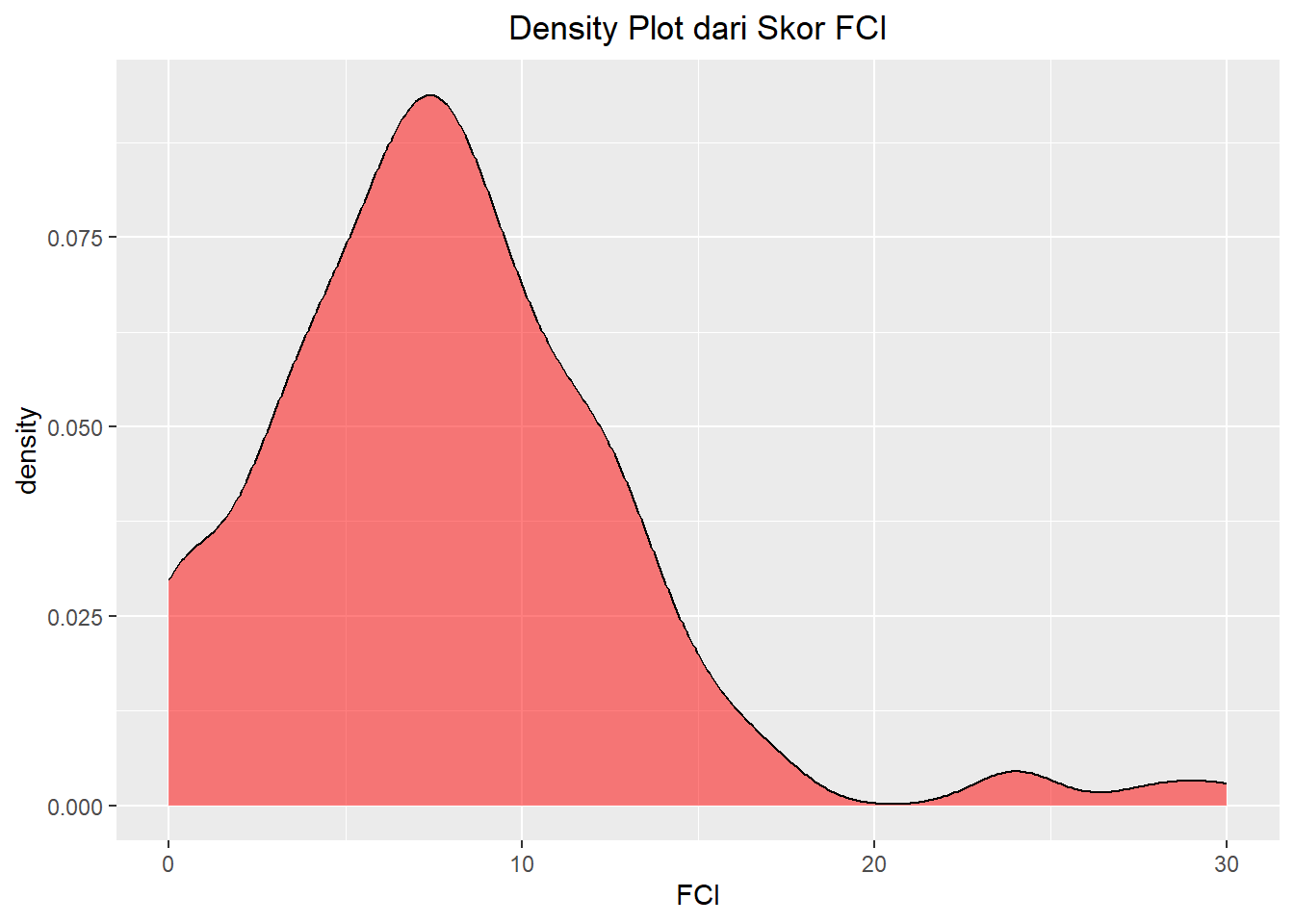
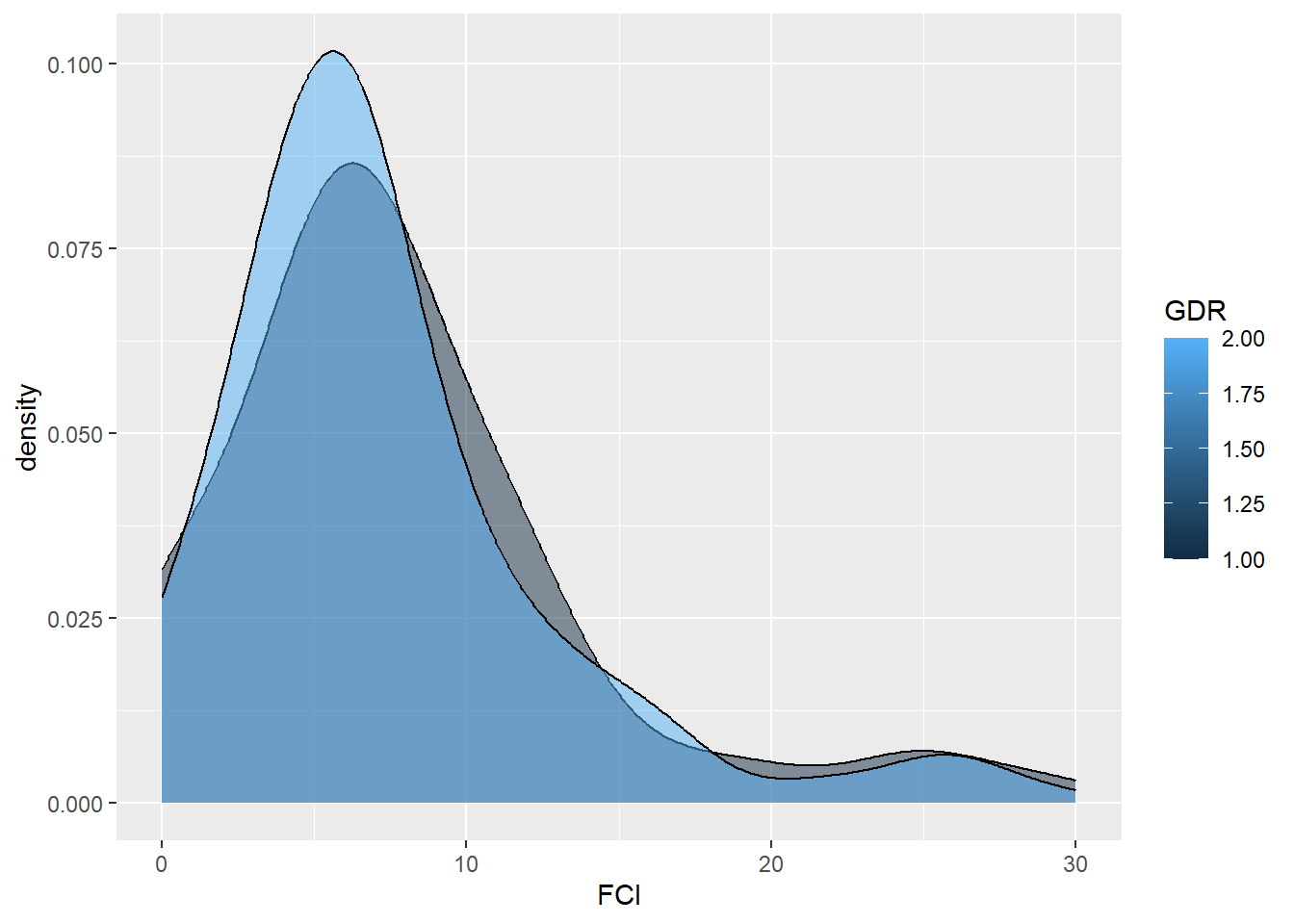
df |>
ggplot(aes(x=FCI, fill = factor(GDR))) +
geom_density( color="#e9ecef", alpha=0.8, position = 'identity') +
labs(fill="Gender", x = "Skor FCI", y = "Frekuensi") +
scale_fill_manual(values=c("blue", "red"), labels = c("Laki-laki", "Perempuan")) +
ggtitle("Histogram Skor FCI antar Gender") +
theme(plot.title = element_text(hjust = 0.5))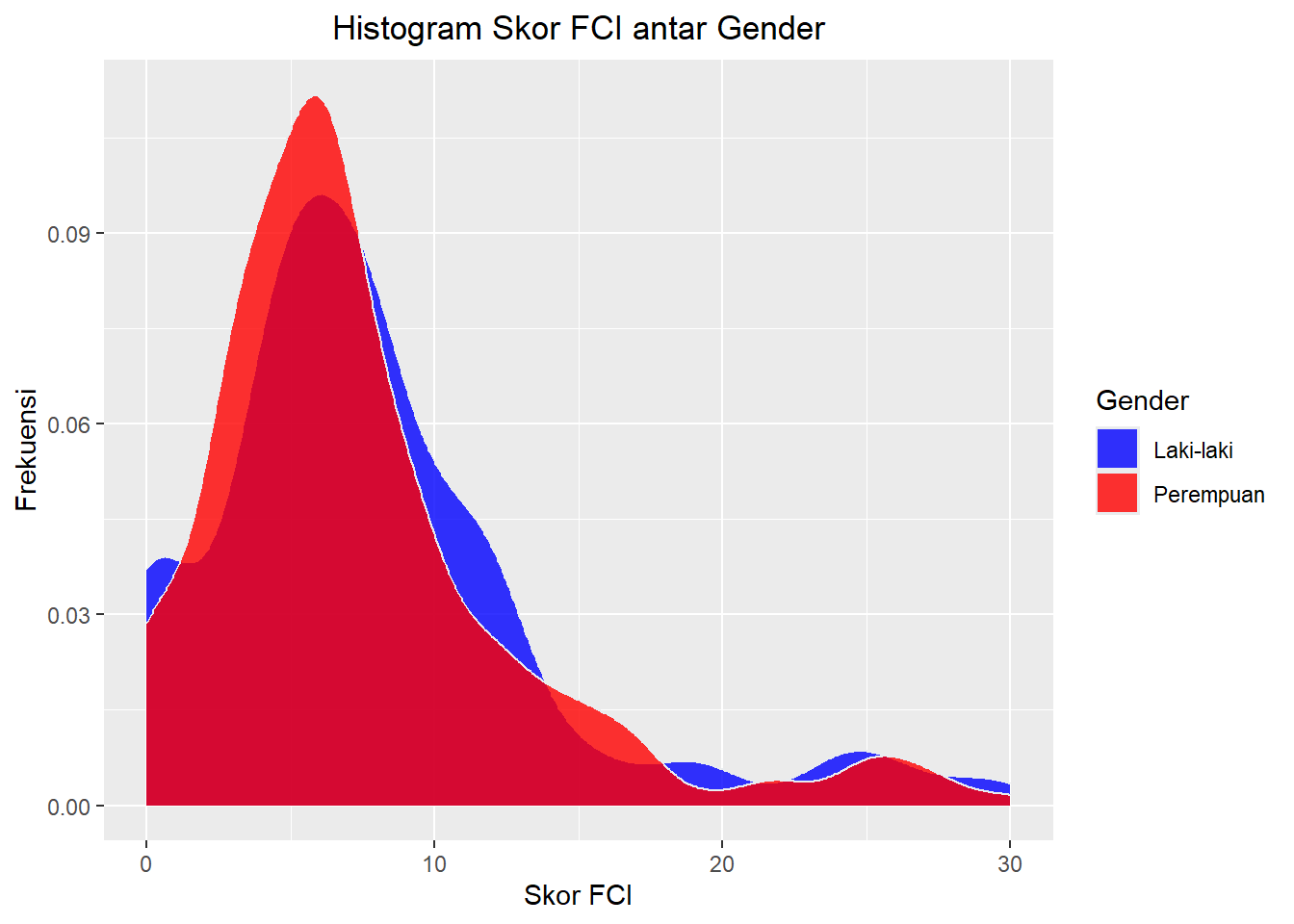
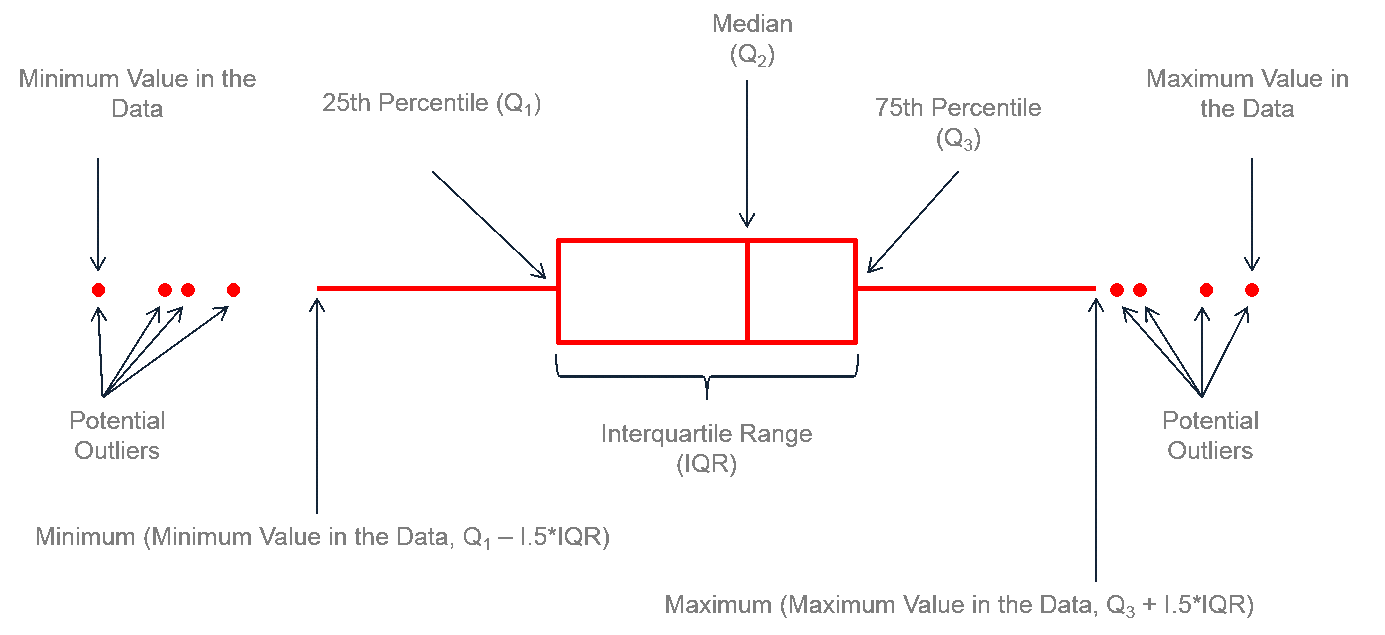
Boxplot
Boxplot adalah visualisasi yang dapat mengilustrasikan nilai rerata, median, maksimum, minumum, jarak inter kuartil, dan data-data pencilan yang “mengganggu” distribusi data kita. Berikut ini adalah anatomi dari sebuah boxplot.
Dengan base R, kita bisa membuat visualisasi boxplot menggunakan fungsi boxplot(). Pada contoh di bawah ini, argumen col diatur menggunakan sistem pewarnaan heksadesimal. Untuk mengakses palet interaktif, kita bisa menggunakan sebuah tool di internet seperti https://www.color-hex.com/color-wheel/ .
boxplot(df$FCI ~ df$GDR, xlab = "Gender", ylab = "Skor FCI", col="#69b3a2")
legend("topleft", legend = c("1 = Laki-laki","2 = Perempuan"), pch=1 , pt.cex = 1, cex = 0.6)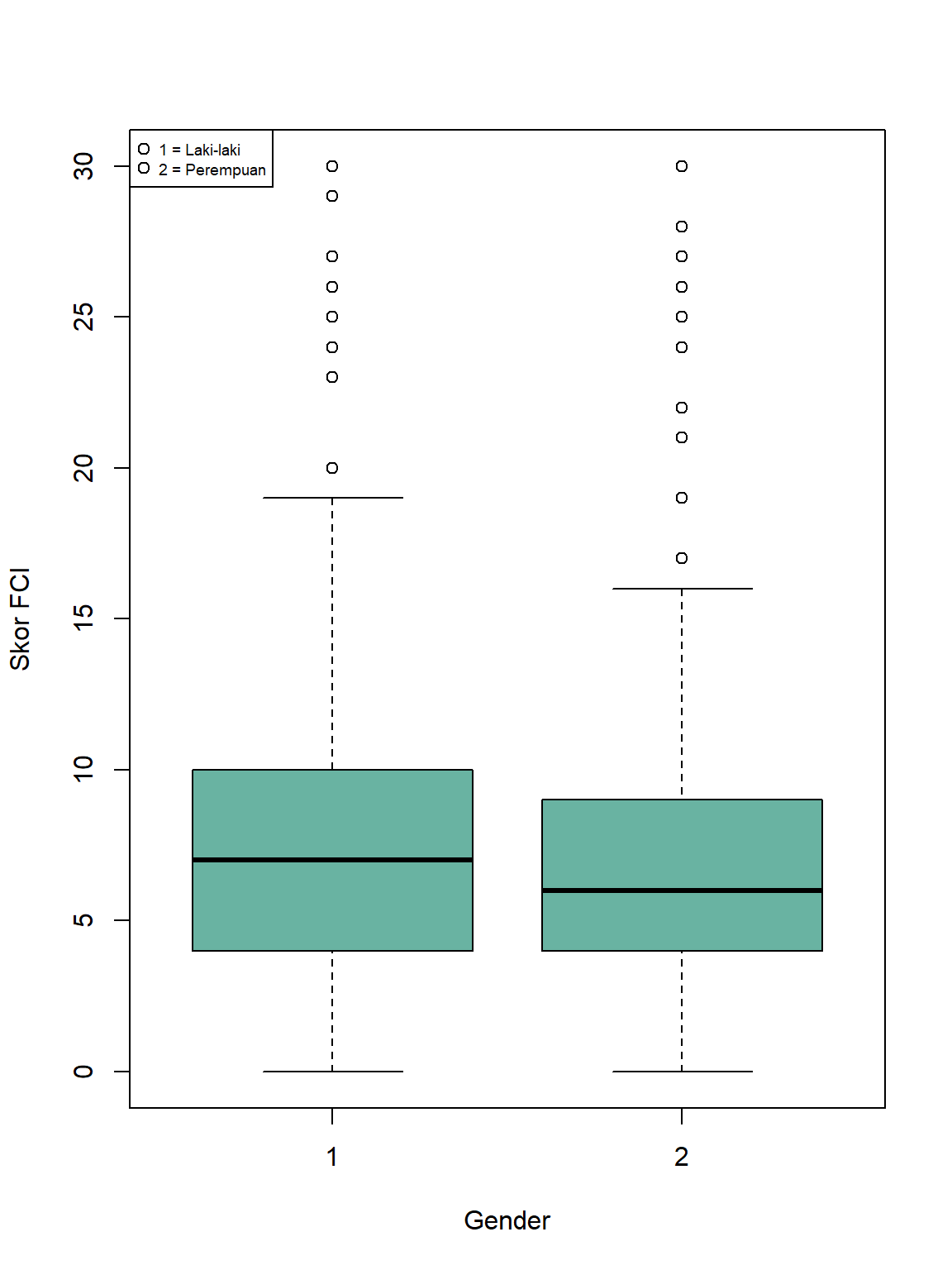
Kita juga bisa membuat visualisasi boxplot dengan menggunakan ggplot2.
Contoh:
df |> ggplot(aes(x=factor(GDR), y=FCI, fill=factor(GDR))) +
geom_boxplot(alpha=0.5) +
labs(fill = "Gender", x = "Gender", y = "Skor FCI") +
scale_fill_manual(values=c("blue", "red"), labels = c("1 : Laki-laki", "2 : Perempuan"))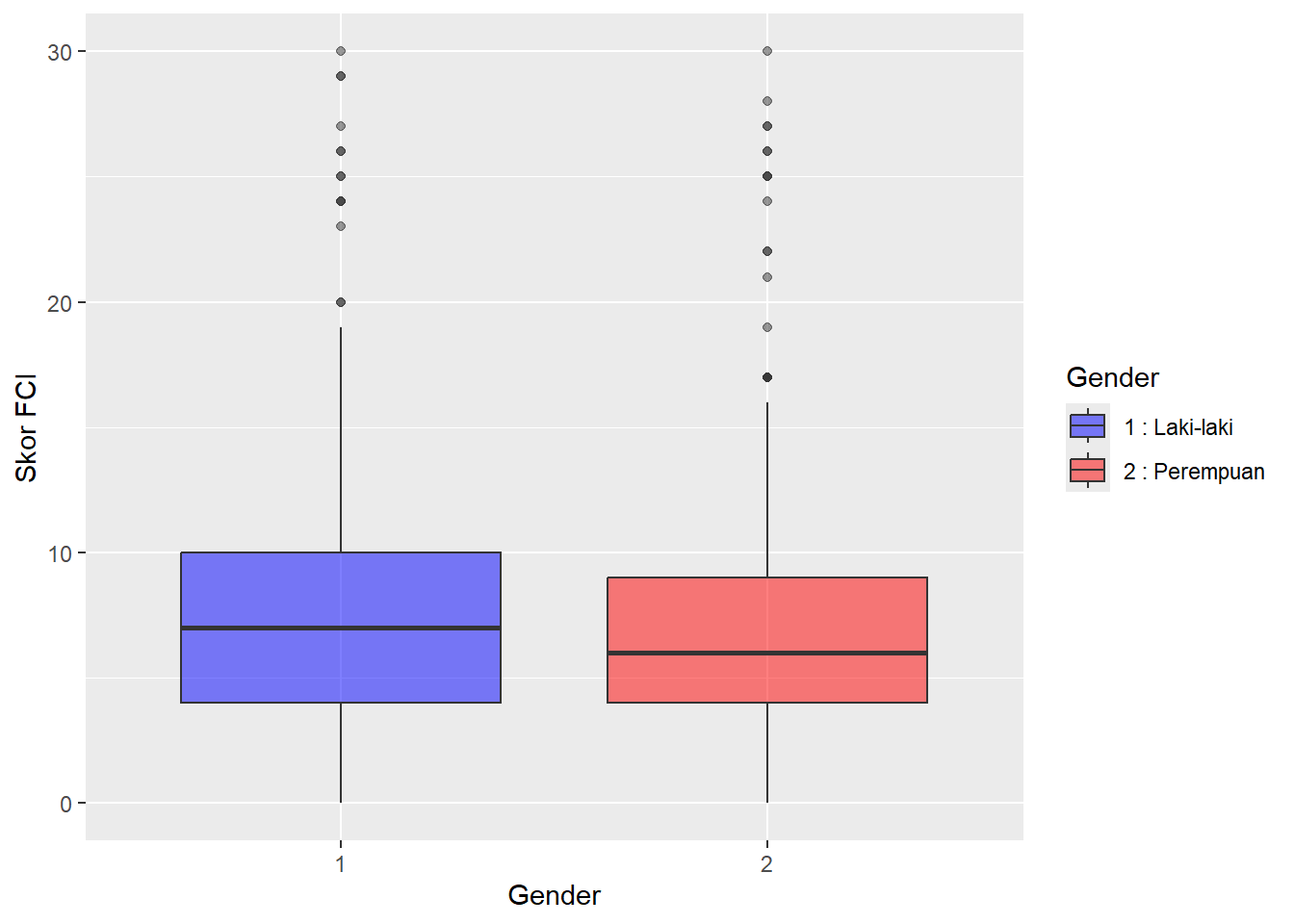
Violin Plot
Violin plot adalah varian lain dari boxplot yang telah kita pelajari sebelumnya. Perbedaannya adalah violin plot mampu mengintegrasikan density plot ke dalam sebuah visualisasinya. Kita hanya bisa membuat violin plot melalui package ggplot2.
Contoh:
df |> ggplot(aes(x=factor(GDR), y=FCI, fill=factor(GDR))) +
geom_violin(adjust=1.5, alpha=0.5) +
labs(fill = "Gender", x = "Gender", y = "Skor FCI")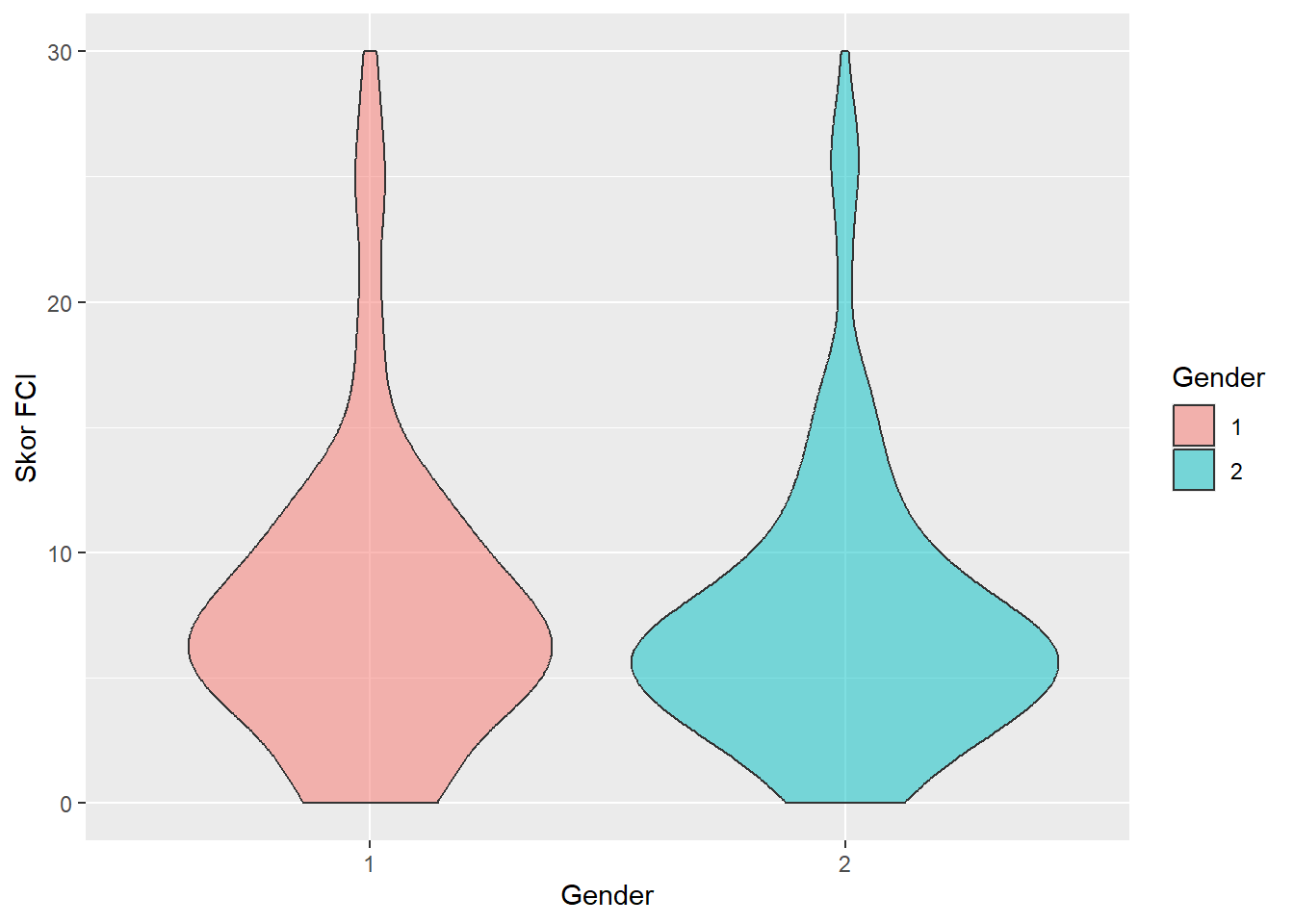
10.4 Visualisasi Asosiasi
Asosiasi (hubungan) antar variabel merupakan masalah penelitian kuantitatif. Kita biasanya mempelajari hubungan variabel bebas (manipulasi) terhadap variabel terikat (respon). Beberapa visualisasi yang dapat kita buat antara lain scatter plot, line plot, dan heatmap.
Scatter Plot
Argumen cex berfungsi untuk mengatur ukuran titik-titik data dan argumen pch berfungsi untuk mengatur bentuk dari titik data secara visual.
Dengan base R, kita akan mengalami kesulitan dalam melakukan modifikasi kode sesuai kebutuhan kita. Kita bisa membuat scatter plot dengan banyak fitur modifikasi dengan ggplot2.
Contoh:
df |> ggplot(aes(x=FCI, y=FMCE, color = factor(DOM), shape = factor(GDR))) +
geom_point(alpha = 0.8, size = 3) +
labs(color = "Domisili", shape = "Jenis Kelamin") +
scale_fill_manual(values=c("blue", "red"), labels = c("1 : Dalam zonasi", "2 : Luar zonasi"))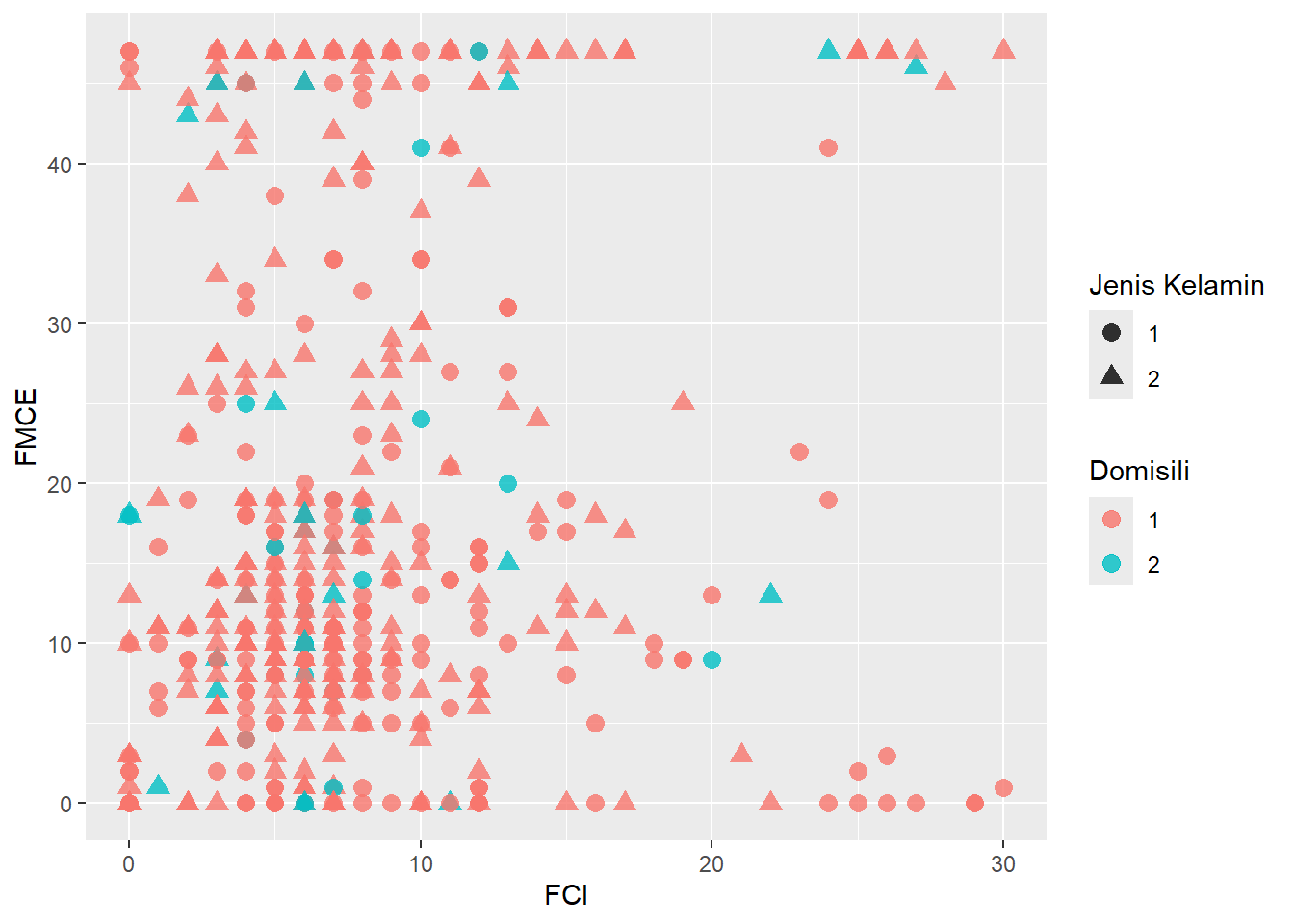
Line Plot
Contoh:
Argumen linewidth diperuntukkan untuk mengatur tebal garis yang dihasilkan. Argumen linetype berfungsi untuk menentukan bentuk dari garis yang dibentuk.
x <- 1:720
y <- cos(x*pi/180)
df_sin <- data.frame(x,y)
df_sin |> ggplot(aes(x=x, y=y)) +
geom_line(linetype = 2, linewidth = 2) +
labs(x = "Sudut (derajat)")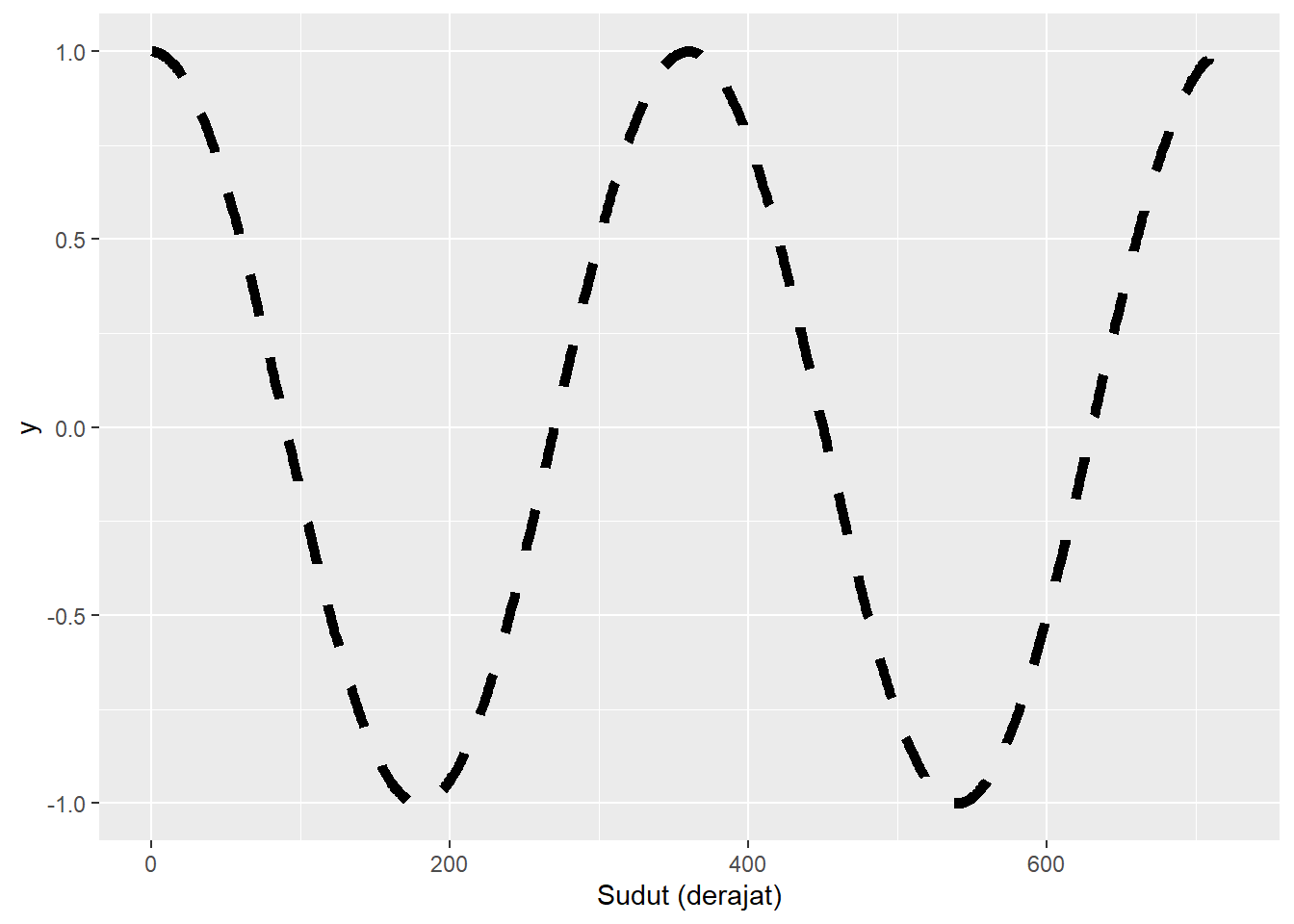
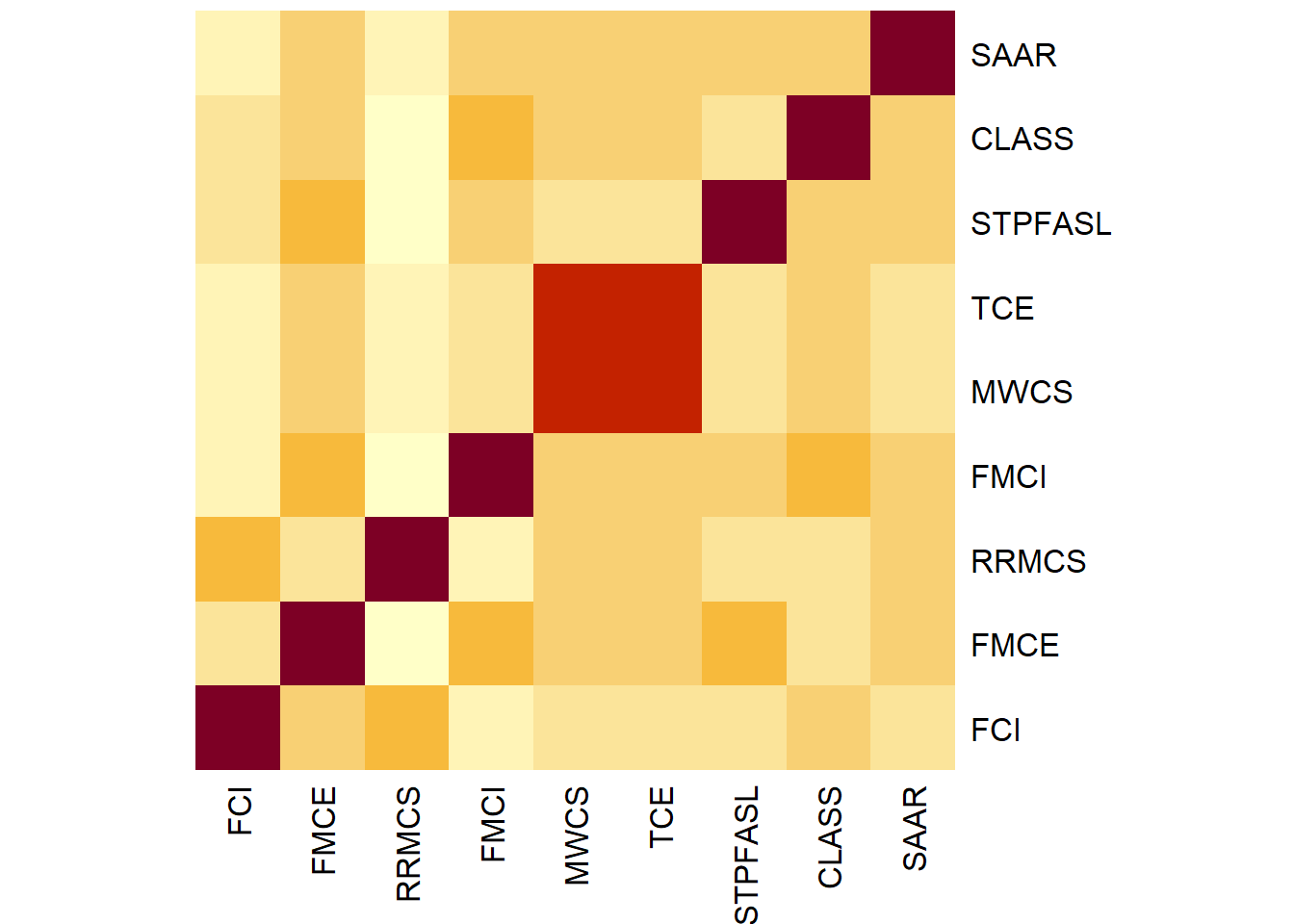
Heat Map
Dalam penelitian ilmu pendidikan, heatmap biasanya digunakan untuk melihat korelasi antara variabel yang terdapat di dalam dataset. Variabel-variabel yang saling berkorelasi memiliki informasi yang bisa diungkap melalui analisis lebih lanjut misalkan analisis regresi, analisis faktor, analisis klaster, dan lain-lain. R telah menyediakan fungsi heatmap().
Contoh:
10.5 Visualisasi Kategorisasi
Diagram Batang (Bar Plot)
Misalkan disini kita sedang membuat diagram batang untuk menampilkan rata-rata skor FCI antara sekolah yang berpartisipasi dalam “spheredata”. Sekarang kita menggunakan fungsi bawaan R untuk membuat diagram batang yaitu barplot().
mean_scores <- tapply(df$FCI, df$SCH, mean)
barplot(mean_scores,
col = c("skyblue", "pink", "black", "green"),
ylim = c(0, 10),
main = "Skor FCI Antar Sekolah",
xlab = "Sekolah",
ylab = "Skor FCI Rata-rata")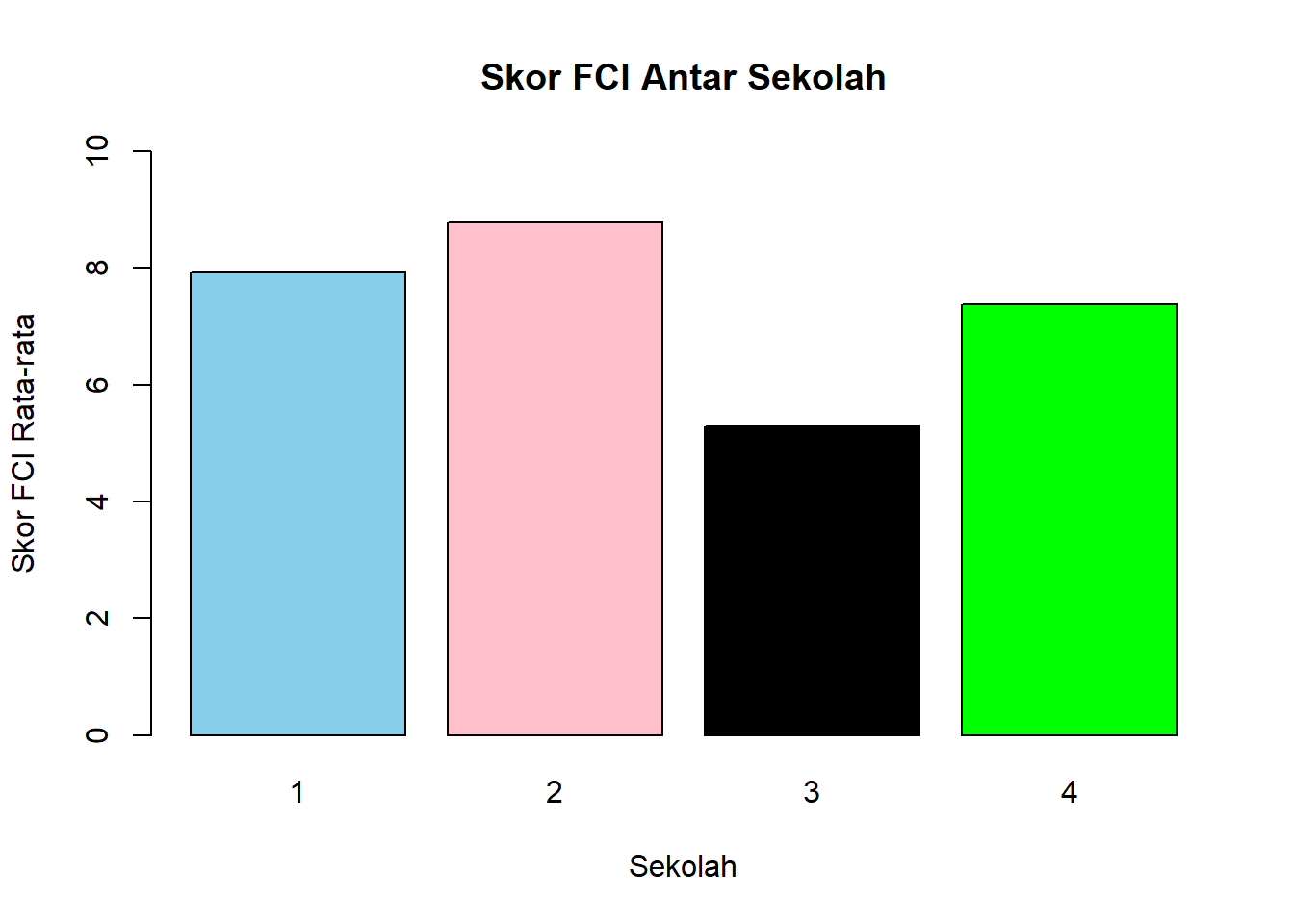
Atau kita bisa membuat diagram batang dengan package ggplot2.
df |>
group_by(SCH) |>
summarise(mean_score = mean(FCI)) |>
ggplot(aes(x = SCH, y = mean_score, fill = factor(SCH))) +
geom_col() +
labs(fill = "Sekolah", x = "Sekolah", y = "Rata-Rata Skor FCI")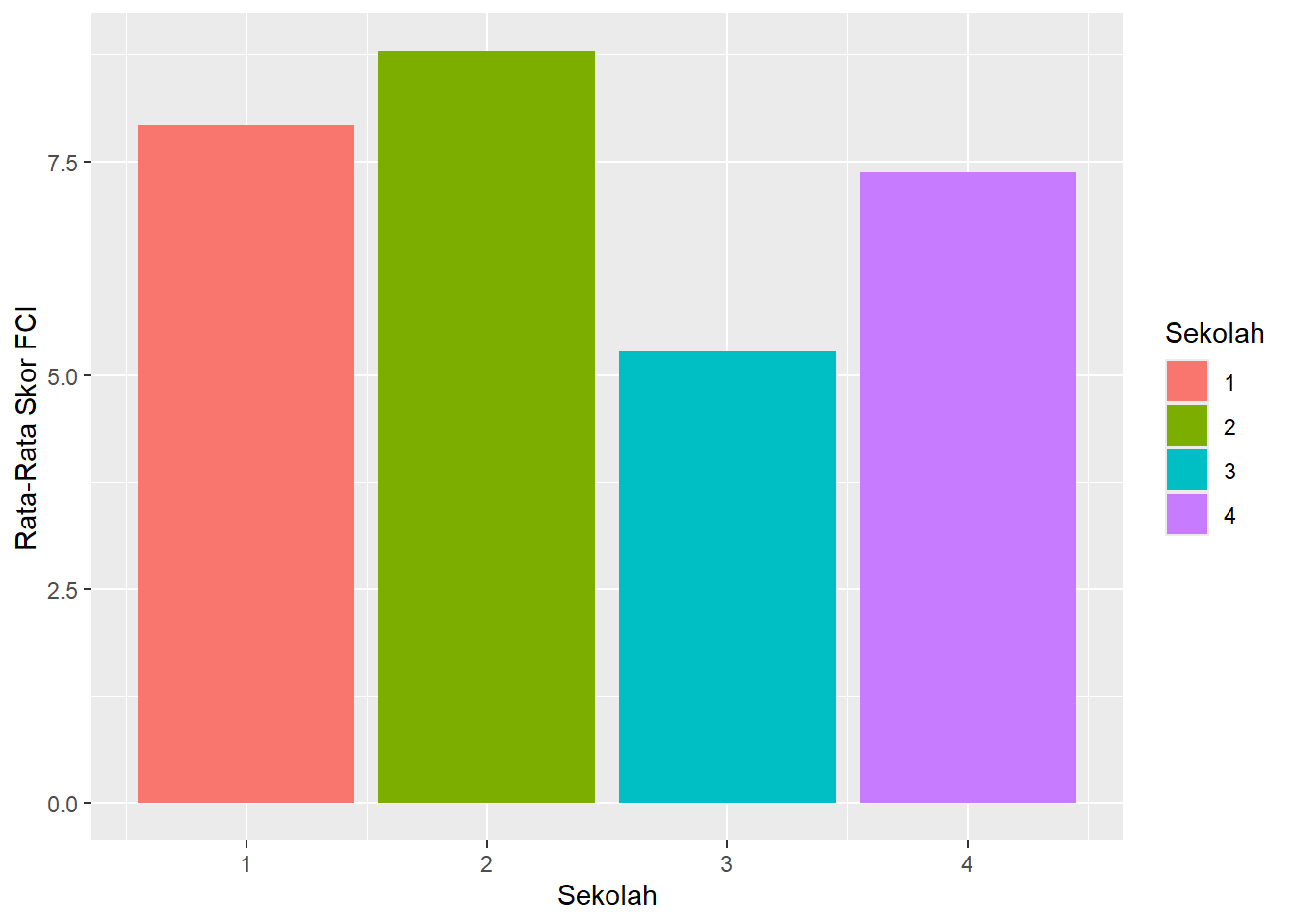
Diagram Pie (Pie Chart)
Diagram pie bermanfaat ketika kita ingin menampilkan proporsi dari setiap kelas kategori di dalam dataset. Disini kita ingin mengetahui proporsi dari pekerjaan ibu siswa yang terekam di dalam dataset “spheredata”.
Contoh:
summary_pekerjaan <- tapply(df$MOTHOCC, df$MOTHOCC, length)
pct <- round(summary_pekerjaan / sum(summary_pekerjaan) * 100, 1)
labels <- paste(c("Wiraswasta", "Petani", "Karyawan Swasta", "Pendidik", "Tenaga Kesehatan", "PNS", "Tidak Bekerja", "Lainnya"), pct, "%")
pie(summary_pekerjaan, main = "Distribusi Pekerjaan Ibu Siswa (n = 497)", labels = labels)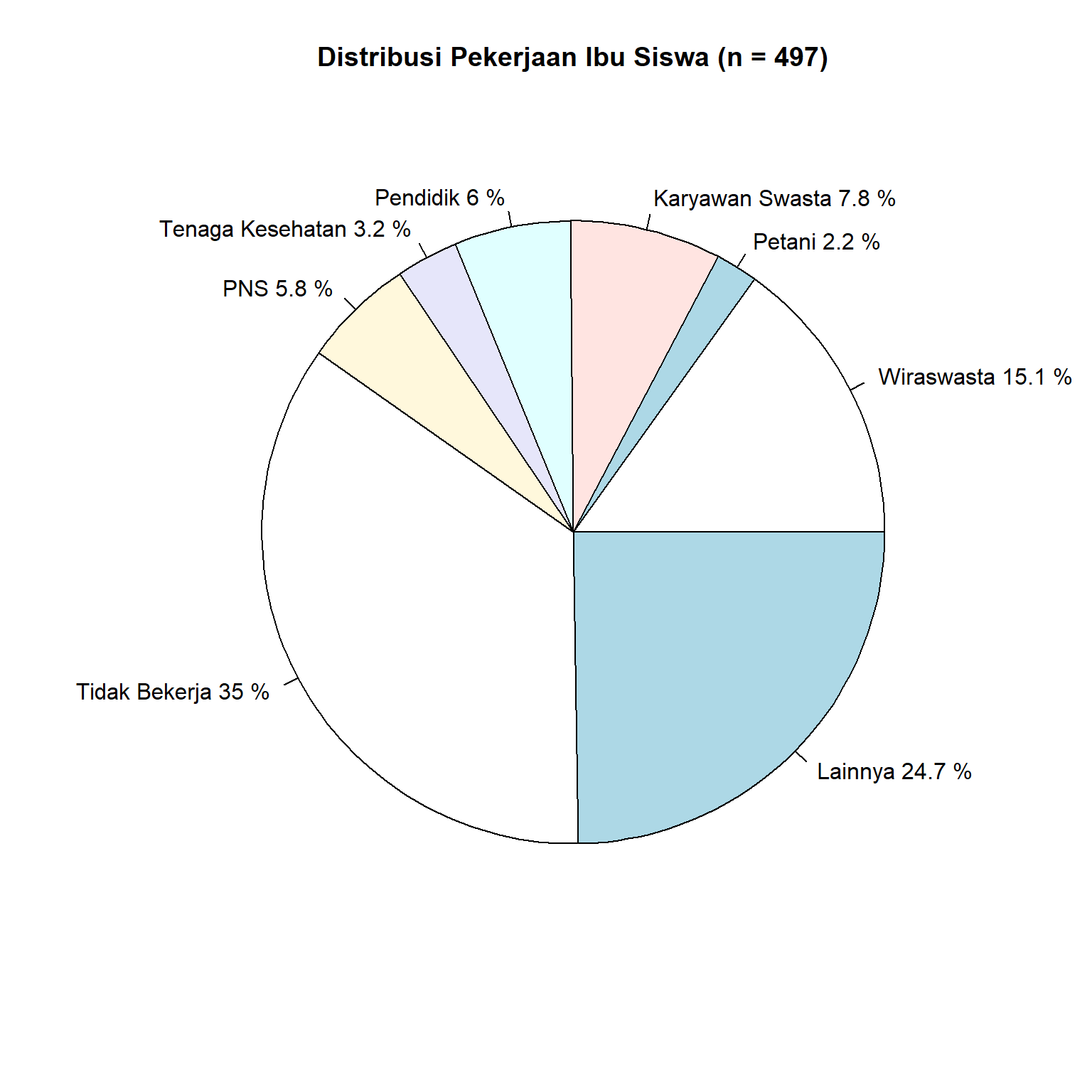
Atau kita bisa juga membuat diagram pie dengan ggplot2.
Contoh:
df |>
group_by(MOTHOCC) |>
summarise(jumlah = n(), .groups = "drop") |>
mutate(persen = round(jumlah / sum(jumlah) * 100, 1)) |>
ggplot(aes(x = "", y = jumlah, fill = factor(MOTHOCC))) +
geom_bar(stat = "identity", width = 1, color = "white") +
coord_polar("y", start = 0) +
labs(title = "Distribusi Pekerjaan Orang Tua Siswa (n = 497)", fill = "Pekerjaan Ibu") +
theme_void() +
geom_text(aes(label = paste0(persen, "%"), x = 1.65),
position = position_stack(vjust = 0.5),
color = "black", size = 3) +
geom_text(aes(label = MOTHOCC, x = 1.375),
position = position_stack(vjust = 0.5),
color = "black", size = 3) +
scale_fill_brewer(palette="Set2", labels = c("1 Wiraswasta", "2 Petani", "4 Karyawan Swasta",
"5 Pendidik", "6 Tenaga Kesehatan", "7 PNS",
"8 Tidak Bekerja", "9 Lainnya"))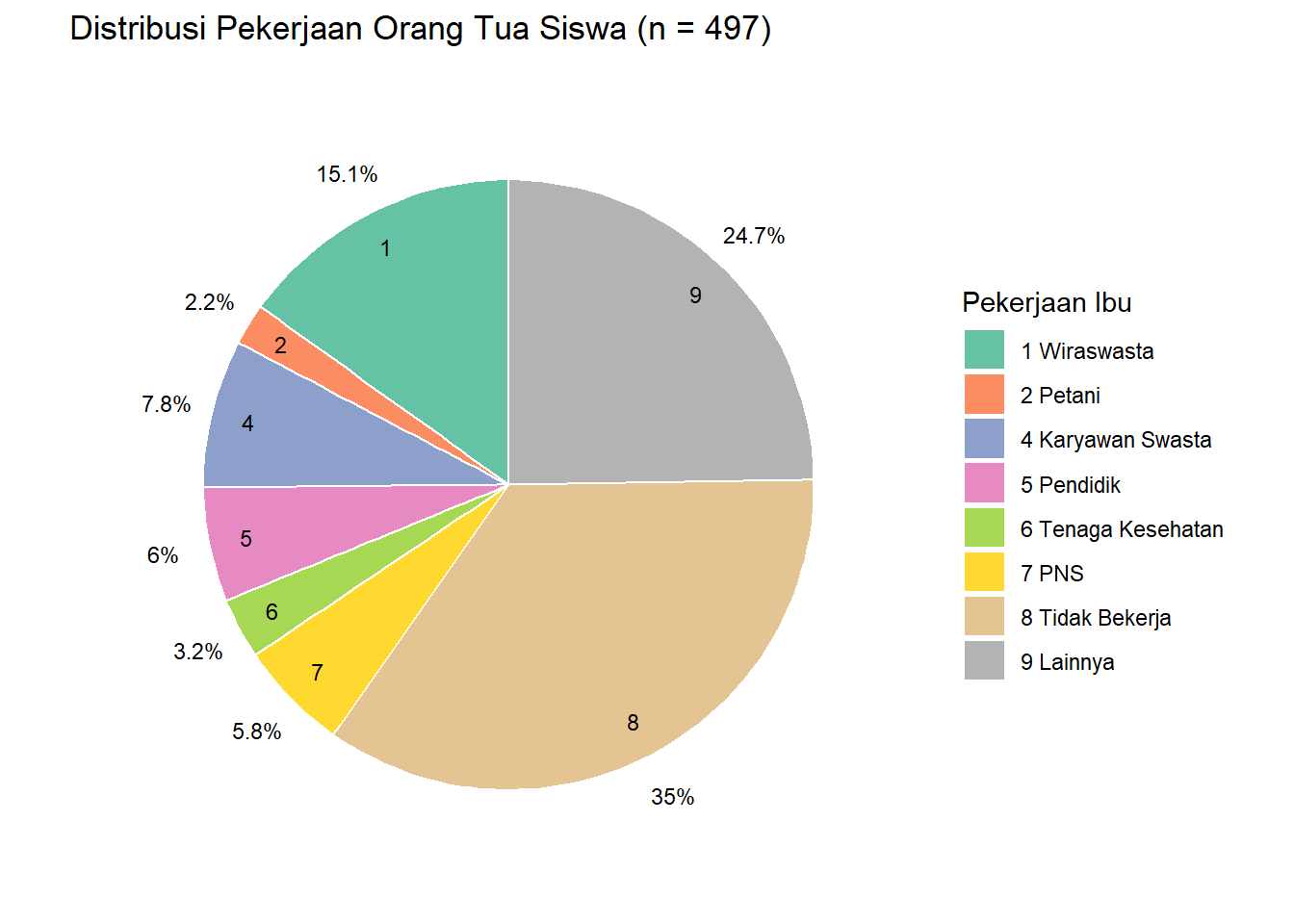
Tentunya masih banyak lagi teknik visualisasi lainnya yang lebih menantang. Pembahasan dari bab ini masih sangat mendasar dan kamu bisa mengeksplorasi melalui sumber-sumber di internet. Salah satu website yang direkomendasikan untuk dipelajari adalah contohnya https://r-graph-gallery.com/.html Silakan mengeksplorasi visualisasi R secara mandiri. Selamat menjelajah!
10.6 Tugas (Project-Based Learning)
Buatlah secara kreatif TIGA buah visualisasi BARU yang bisa kamu ciptakan melalui dataset “spheredata”. Interpretasikan dan ceritakan maksud dan tujuan dari visualisasi tersebut. Informasi apa yang ingin disampaikan? Tulis jawaban Anda sebagai sebuah “artikel” singkat terdiri dari Pendahuluan, Tujuan Visualisasi, Visualisasi, Analisis dan Pembahasan. Tuliskanlah pekerjaan Anda melalui R Notebook (.RMD) dan sajikanlah hasil analisis di depan teman sekelas dan pendidik pemrograman pada mata kuliah ini! Kumpulkan file .RMD via Google Classroom!
10.7 Rubrik Penilaian Pembelajaran
Nama Mahasiswa : NIM :
| Aspek | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Aktivitas pemrograman | … | … | … | … |
| Kelancaran tugas | … | … | … | … |
| Kualitas pekerjaan | … | … | … | … |
| Keterbukaan masukan | … | … | … | … |
Definisi
- Aktivitas pemrograman mengukur keterlibatan mahasiswa dalam proses mengikuti pelajaran.
- Kelancaran tugas mengukur sejauh mana mahasiswa mampu mengikuti prosedur pemrograman yang telah dicontohkan dalam buku ini.
- Kualitas pekerjaan mengukur kemampuan mahasiswa dalam menggunakan komputernya untuk melakukan pemrograman dengan R.
- Keterbukaan masukan mengukur sejauh mana kualitas presentasi mahasiswa dan menerima masukan dan tanggapan dari temannya yang lain.
10.8 Penutup
Pada bab ini, kita mempelajari aspek yang paling indah dari sebuah proyek analisis data yaitu visualisasi. Beberapa visualisasi bisa kita terapkan nantinya untuk mendukung dan mempresentasikan hasil analisis kita kepada orang banyak. Tentunya masih banyak kreasi yang bisa kamu ciptakan dari visualisasi-visualisasi ini. Dataset yang berbeda dan tujuan analisis yang lain seharusnya memiliki karakteristik visualisasi yang diinginkan. Teruslah mengeksplorasi visualisasi data. Selamat belajar!